


There is an emerging demand on efficiently archiving and (temporal) querying different versions of evolving semantic Web data. As novel archiving systems are starting to address this challenge, foundations/standards for benchmarking RDF archives are needed to evaluate its storage space efficiency and the performance of different retrieval operations.
To this end, we have developed a BEnchmark of RDF ARchives (BEAR), a test suite composed of three real-world datasets together with queries with varying complexity, covering a broad range of archiving use cases.
BEAR-A is composed of 58 weekly snapshots from the Dynamic Linked Data Observatory. BEAR-A provides triple pattern queries to test atomic queries such as Materialization, Diff, Version, etc.
The BEAR-B dataset has been compiled from DBpedia Live changesets over the course of three months and contains the 100 most volatile resources along with their updates and real-world triple pattern queries from user logs.
BEAR-C used the Open Data Portal Watch project to take the datasets descriptions of the European Open Data portal for 32 weeks. With the help of Open Data experts, we created 10 complex queries that retrieve different information from datasets and files.
Note: additional (non-mandatory) operations can be found in the BEAR-A related article.
We build our RDF archive on the data hosted by the Dynamic Linked Data Observatory. BEAR-A data are composed of the first 58 weekly snapshots, i.e. 58 versions, from this corpus. We removed the context information and manage the resultant set of triples, disregarding duplicates. We also replaced Blank Nodes with Skolem IRIs (with a prefix http://example.org/bnode/) in order to simplify the computation of diffs.
We report the data configuration features that are relevant for the benchmark. The following table lists basic statistics of the dataset.
| Versions | Triples in Version 0 | Triples in Version 57 | Growth | Change ratio | Change ratio adds | Change ratio deletes | Static core | Version-oblivious triples |
|---|---|---|---|---|---|---|---|---|
| 58 | 30m | 66m | 101% | 31% | 33% | 27% | 3.5m | 376m |
Number of statements per version:
 Data growth:
Data growth:

As can be seen, although the number of statement in the last version doubles the initial size, the mean version data growth between versions is almost marginal (101%). A closer look to the figures above allows one to identify that the latest versions are highly contributing to this increase. Similarly, the version change ratios point to the concrete adds and delete operations. A mean of 31% of the data change between two versions.
The number of version-oblivious triples (376m) points to a relatively low number of different triples in all the history if we compare this against the number of versions and the size of each version. Finally, note the remarkably small static core (3.5m).
We present below the RDF vocabulary (different subjects, predicates and objects) per version and per delta (adds and deletes). As can be seen, the number of different subjects and predicates remains stable except for the noticeable increase in the latests versions, as already identified in the number of statements per versions. However, the number of added and deleted subjects and objects fluctuates greatly and remain high (one order of magnitude of the total number of elements). In turn, the number or predicates are proportionally smaller, but it presents a similar behaviour.
Subjects per version: Predicates per version:
Predicates per version:
 Objects per version:
Objects per version:

| Policy | Description | Size (tar.gz) | Download |
|---|---|---|---|
| IC | One Ntriples file per version | 22 GB | alldata.IC.nt.tar.gz |
| CB | Two Ntriples files (added and deleted triples) per version | 13 GB | alldata.CB.nt.tar.gz |
| TB | One NQuad file where the named graph annotates the version/s of the triple | 4 GB | alldata.TB.nq.gz |
| CBTB | One NQuad file where the named graph annotates the version/s where the triple has been added/removed | 14 GB | alldata.CBTB.nq.gz |
BEAR-A provides SPARQL triple pattern queries (See SPARQL spec for further information on triple patterns) and their results in all 58 versions. The evaluation consists then in computing the defined Materialization, Query and Version operations over them.
Triple pattern queries are split in low and high number of results (cardinality). 50 triple pattern queries S??, ?P? and ??O are carefully selected to provide a small deviation between versions, such that the difference in performance results can be only explain by the efficiency of the underlying archiving system. Random S?O, SP? and ?PO are selected from the previous ones. We additionally sample 50 (SPO) queries from the static core (present in all versions).
| Triple Pattern Query | Cardinality | Number | Download Queries | Mat Results | Diff Results | Ver Results |
|---|---|---|---|---|---|---|
| S?? | Low | 50 | Get queries | Get mat results | Get diff results | Get ver results |
| High | 50 | Get queries | Get mat results | Get diff results | Get ver results | |
| ?P? | Low | 6 | Get queries | Get mat results | Get diff results | Get ver results |
| High | 10 | Get queries | Get mat results | Get diff results | Get ver results | |
| ??O | Low | 50 | Get queries | Get mat results | Get diff results | Get ver results |
| High | 50 | Get queries | Get mat results | Get diff results | Get ver results | |
| SP? | Low | 50 | Get queries | Get mat results | Get diff results | Get ver results |
| High | 13 | Get queries | Get mat results | Get diff results | Get ver results | |
| ?PO | Low | 43 | Get queries | Get mat results | Get diff results | Get ver results |
| High | 46 | Get queries | Get mat results | Get diff results | Get ver results | |
| S?O | Low | 50 | Get queries | Get mat results | Get diff results | Get ver results |
| High | N/A | |||||
| SPO | N/A | 50 | Get queries | Get mat results | Get diff results | Get ver results |
The BEAR-B dataset has been compiled from DBpedia Live changesets over the course of three months (August to October 2015). DBpedia Live records all updates to Wikipedia articles and hence re-extracts and instantly updates the respective DBpedia Live resource descriptions.
BEAR-B contains the resource descriptions of the 100 most volatile resources along with their updates. The most volatile resource (dbr:Deaths_in_2015) changes 1,305 times, the least volatile resource contained in the dataset (dbr:Once_Upon_a_Time_(season_5)) changes 263 times.
As dataset updates in DBpedia Live occur instantly, for every single update the dataset shifts to a new version. In practice, one would possibly aggregate such updates in order to have less dataset modifications. Therefore, we also aggregated these updates on an hourly and daily level. Hence, we get three time granularities from the changesets for the very same dataset: instant (21,046 versions), hour (1,299 versions), and day (89 versions).
We report the data configuration features that are relevant for the benchmark. The following table lists basic statistics of the dataset.
| Granularity | Versions | Triples in Version 0 | Triples in Version 57 | Growth | Change ratio | Change ratio adds | Change ratio deletes | Static core | Version-oblivious triples |
|---|---|---|---|---|---|---|---|---|---|
| instant | 21,046 | 33,502 | 43,907 | 100.001% | 0.011% | 0.007% | 0.004% | 32,094 | 234,588 |
| hour | 1,299 | 33,502 | 43,907 | 100.090% | 0.304% | 0.197% | 0.107% | 32,303 | 178,618 |
| day | 89 | 33,502 | 43,907 | 100.744% | 1.778% | 1.252% | 0.526% | 32,448 | 83,134 |
The dataset grows almost continuously from 33,502 triples to 43,907 triples. Since the time granularities differ in the number of intermediate versions, they show different change characteristics: a longer update cycle also results in more extensive updates between versions, the average version change ratio increases from very small portions of 0.011% for instant updates to 1.8% at the daily level.
It can also be seen that the aggregation of updates leads to omission of changes: whereas the instant updates handle 234,588 version-oblivious triples, the daily aggregates only have 83,134 (hourly: 178,618), i.e. a reasonable number of triples exists only for a short period of time before they get deleted again. Likewise, from the different sizes of the static core, we see that triples which have been deleted at some point are reinserted after a short period of time (in the case of DBpedia Live this may happen when changes made to a Wikipedia article are reverted shortly after).
| Granularity | Policy | Description | Size (tar.gz) | Download | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| instant | IC | One Ntriples file per version | 12 GB | alldata.IC.nt.tar.gz | ||||||||||
| CB | Two Ntriples files (added and deleted triples) per version | 16 MB | alldata.CB.nt.tar.gz | |||||||||||
| CBTB | One NQuad file where the named graph annotates the version/s where the triple has been added/removed | 5.2 MB | alldata.CBTB.nq.gz | |||||||||||
| hour | IC | One Ntriples file per version | 467 MB | alldata.IC.nt.tar.gz | ||||||||||
| CB | Two Ntriples files (added and deleted triples) per version | 4.1 MB | alldata.CB.nt.tar.gz | |||||||||||
| TB | One NQuad file where the named graph annotates the version/s of the triple | 189 MB | alldata.TB.nq.gz | |||||||||||
| CBTB | One NQuad file where the named graph annotates the version/s where the triple has been added/removed | 3.1 MB | alldata.CBTB.nq.gz | |||||||||||
| day | IC | One Ntriples file per version | 32 MB | alldata.IC.nt.tar.gz | ||||||||||
| CB | Two Ntriples files (added and deleted triples) per version | 1.1 MB | alldata.CB.nt.tar.gz | |||||||||||
| TB | One NQuad file where the named graph annotates the version/s of the triple | 1.1 MB | alldata.TB.nq.gz | |||||||||||
| CBTB | One NQuad file where the named graph annotates the version/s where the triple has been added/removed | 1.4 MB | alldata.CBTB.nq.gz | |||||||||||
BEAR-B exploits the real-world usage of DBpedia to provide realistic queries. Thus, we extract the 200 most frequent triple patterns from the DBpedia query set of Linked SPARQL Queries dataset (LSQ) and filter those that produce results in our BEAR-B corpus. We then obtain a batch of 62 lookup queries, mixing (?P?) and (?PO) queries. The evaluation consists then in computing the defined Materialization, Query and Version operations over them. Finally, we build 20 join cases using the selected triple patterns.
| Triple Pattern Query | Number | Download Queries | Granularity | |||||
|---|---|---|---|---|---|---|---|---|
| Hour | Day | |||||||
| Mat Results | Diff Results | Ver Results | Mat Results | Diff Results | Ver Results | |||
| ?P? | 49 | Get queries | Get mat results | Get diff results | Get ver results | Get mat results | Get diff results | Get ver results |
| ?PO | 13 | Get queries | Get mat results | Get diff results | Get ver results | Get mat results | Get diff results | Get ver results |
| Join Queries | Number | Download Queries | Granularity | |
|---|---|---|---|---|
| Hour | Day | |||
| Subject-Objet and Subject-Subject joins | 20 | Get queries | Get join results | Get join results |
The BEAR-C dataset is taken from the Open Data Portal Watch project. For this version of BEAR, we decided to take the datasets descriptions of the European Open Data portal for 32 weeks, or 32 snapshots respectively.
Note that, as in BEAR-A, we also replaced Blank Nodes with Skolem IRIs (with a prefix http://example.org/bnode/) in order to simplify the computation of diffs.
We report the data configuration features that are relevant for the benchmark. The following table lists basic statistics of the dataset.
| Versions | Triples in Version 0 | Triples in Version 57 | Growth | Change ratio | Change ratio adds | Change ratio deletes | Static core | Version-oblivious triples |
|---|---|---|---|---|---|---|---|---|
| 32 | 485,179 | 563,738 | 100.478% | 67.617% | 33.671% | 33.946% | 178,484 | 9,403,540 |
Number of statements per version:
 Data growth:
Data growth:

Each snapshot consists of roughly 500m triples with a very limited growth as most of the updates are modifications on the metadata, i.e. adds and deletes report similar figures.
We present below the RDF vocabulary (different subjects, predicates and objects) per version and per delta (adds and deletes). As can be seen, most of the updates are modifications on the metadata, i.e. adds and deletes report similar figures. Note also that this dynamicity is also reflected in the subject and object vocabulary, whereas the metadata is always described with the same predicate vocabulary, in spite of a minor modification in version 24 and 25.
Subjects per version: Predicates per version:
Predicates per version:
 Objects per version:
Objects per version:

| Policy | Description | Size (tar.gz) | Download |
|---|---|---|---|
| IC | One Ntriples file per version | 241 MB | alldata.IC.nt.tar.gz |
| CB | Two Ntriples files (added and deleted triples) per version | 201 MB | alldata.CB.nt.tar.gz |
| TB | One NQuad file where the named graph annotates the version/s of the triple | 133 MB | alldata.TB.nq.gz |
| CBTB | One NQuad file where the named graph annotates the version/s where the triple has been added/removed | 233 MB | alldata.CBTB.nq.gz |
BEAR-C provides complex queries that, although they cannot be resolved in current archiving strategies in a straightforward and optimized way, they could help to foster the development and benchmarking of novel strategies and query resolution optimizations in archiving scenarios.
BEAR-C offers 10 queries that retrieve different information from datasets and files (referred to as distributions, where each dataset refers to one or more distributions) in the European Open Data portal. The evaluation consists then in computing the defined Materialization, Query and Version operations over them.
| Query | |
|---|---|
| Q1 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
?dataset rdf:type dcat:Dataset .
?dataset dcat:distribution ?distribution .
?distribution dcat:accessURL ?URL .
}
|
| Q2 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
?dataset rdf:type dcat:Dataset .
?dataset dc:modified ?modified_date .
}
|
| Q3 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
?dataset rdf:type dcat:Dataset .
?dataset dcat:contactPoint ?contact .
?contact vcard:fn ?name.
OPTIONAL{
?contact vcard:hasEmail ?email .
}
}
|
| Q4 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX eu: <http://ec.europa.eu/geninfo/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
?dataset rdf:type dcat:Dataset .
?dataset dc:title ?title .
?dataset dcat:distribution ?distribution .
?distribution dcat:accessURL ?URL .
?distribution dc:license eu:legal_notices_en.htm .
FILTER regex(?title, "region")
}
|
| Q5 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
{
?dataset rdf:type dcat:Dataset .
?dataset dc:title ?title .
?dataset dcat:distribution ?distribution .
?distribution dcat:accessURL ?URL .
?distribution dc:description "Austria" .
}
UNION
{
?dataset rdf:type dcat:Dataset .
?dataset dc:title ?title .
?dataset dcat:distribution ?distribution .
?distribution dcat:accessURL ?URL .
?distribution dc:description "Germany" .
}
}
|
| Q6 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
?dataset rdf:type dcat:Dataset .
?dataset dc:title ?title .
?dataset dc:issued ?date .
?dataset dc:modified ?date .
}
|
| Q7 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
?dataset rdf:type dcat:Dataset .
?dataset dc:title ?title .
?dataset dc:issued ?date .
?dataset dcat:distribution ?distribution .
?distribution dcat:accessURL ?URL .
FILTER (?date>"2014-12-31T23:59:59"^^xsd:dateTime)
}
|
| Q8 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
?dataset rdf:type dcat:Dataset .
?dataset dc:title ?title .
?dataset dcat:distribution ?distribution .
?distribution dcat:accessURL ?URL .
?distribution dcat:mediaType "text/csv" .
?distribution dc:title ?filetitle .
?distribution dc:description ?description .
}
|
| Q9 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
?dataset rdf:type dcat:Dataset .
?dataset dc:title ?title .
?distr1 dcat:distribution ?dataset .
?distr1 dcat:accessURL ?URL1 .
?distr1 dcat:mediaType "text/csv" .
?distr1 dc:title ?titleFile1 .
?distr1 dc:description ?description1 .
?distr2 dcat:distribution ?dataset .
?distr2 dcat:accessURL ?URL2 .
?distr2 dcat:mediaType "text/tab-separated-values" .
?distr2 dc:title ?titleFile2 .
?distr2 dc:description ?description2 .
}
|
| Q10 |
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
{
?dataset rdf:type dcat:Dataset .
?dataset dc:title ?title .
?dataset dcat:distribution ?distribution .
?distribution dcat:accessURL ?URL .
?distribution dcat:mediaType ?mediaType .
?distribution dc:title ?filetitle .
?distribution dc:description ?description .
}
ORDER BY ?filetitle
LIMIT 100 OFFSET 100
|
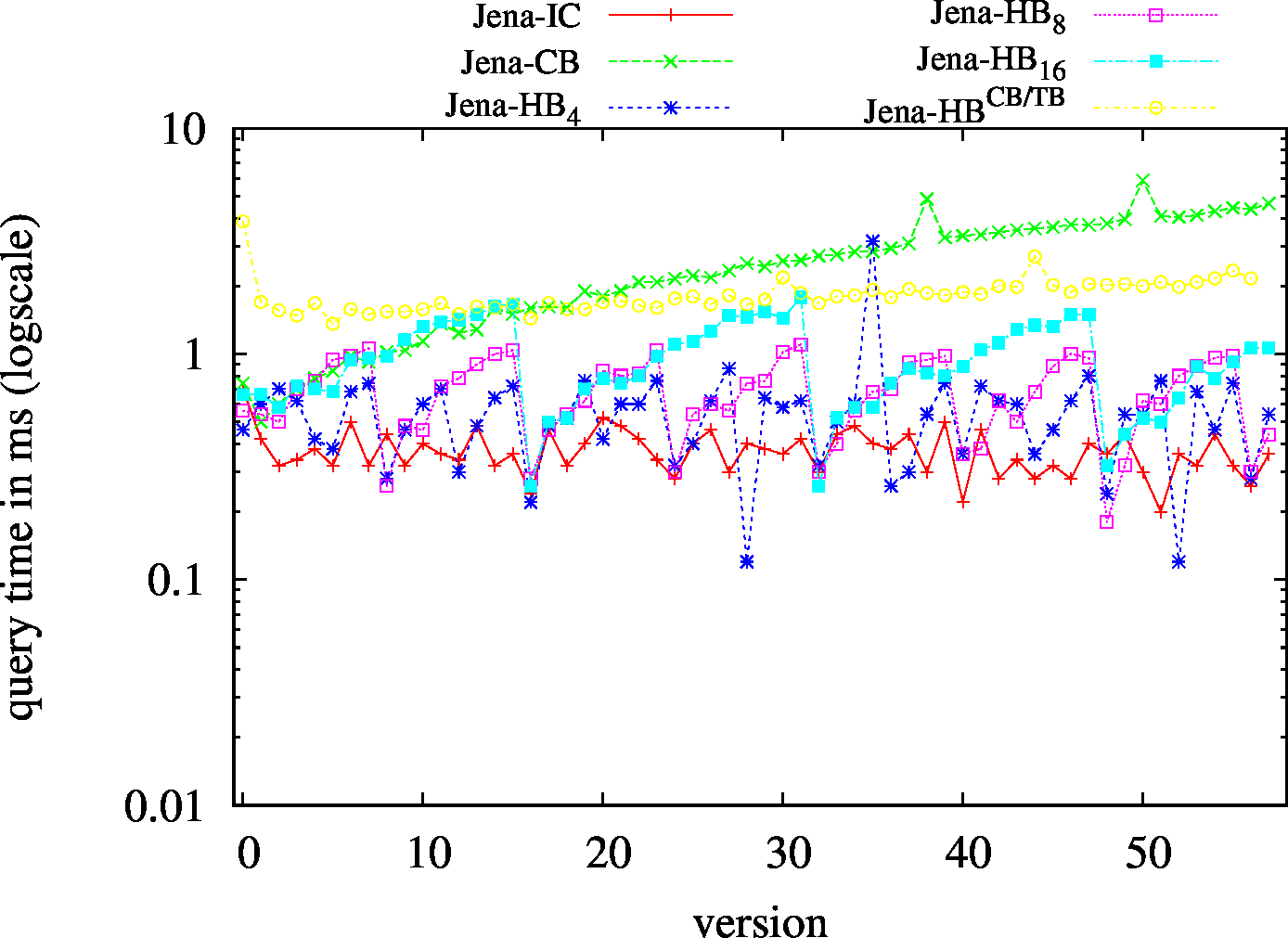
We report the results as of March 2017 in which BEAR-A and BEAR-B was used to test the performance of the following RDF archiving systems (download the source code in our Github repository):
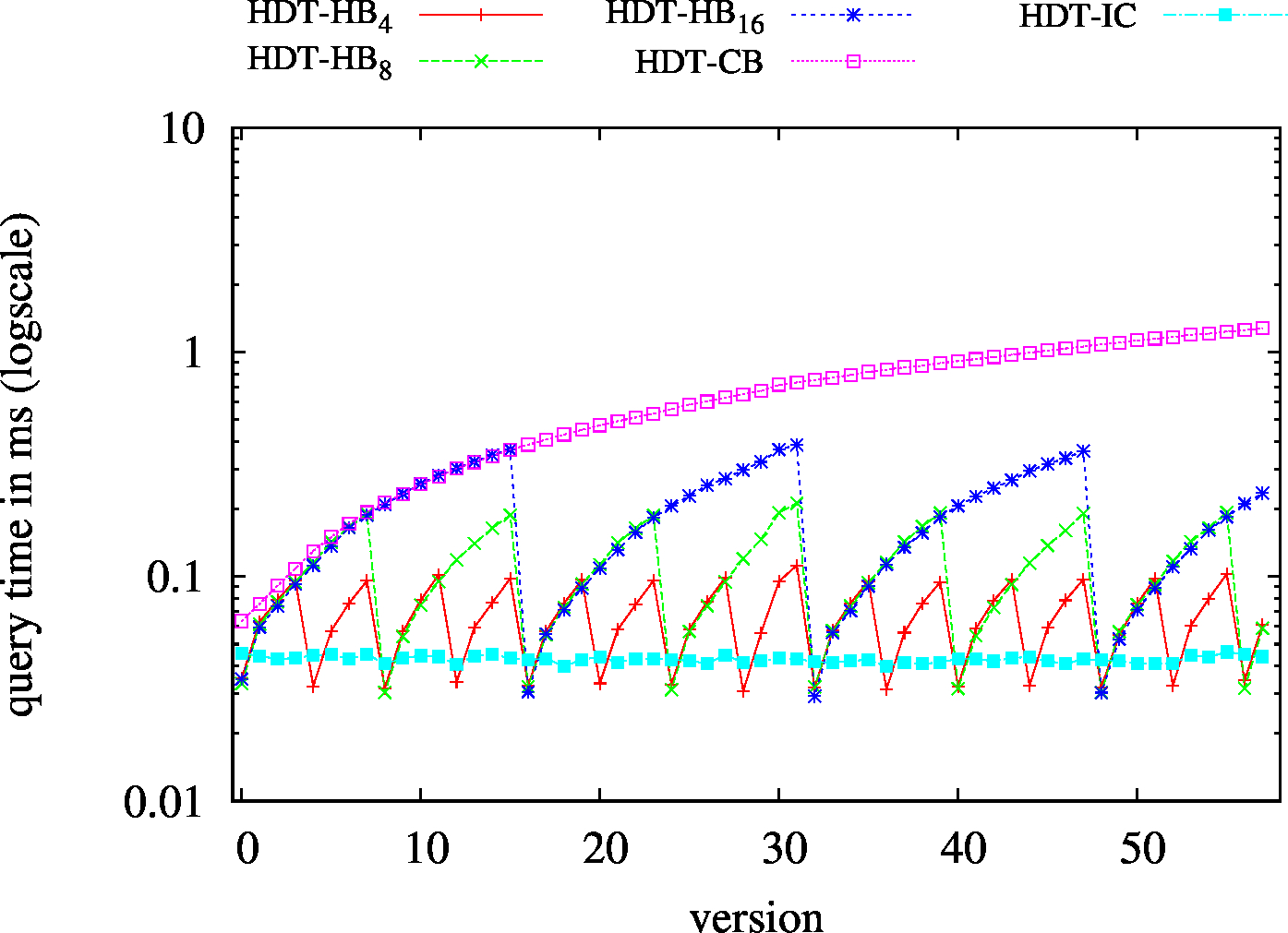
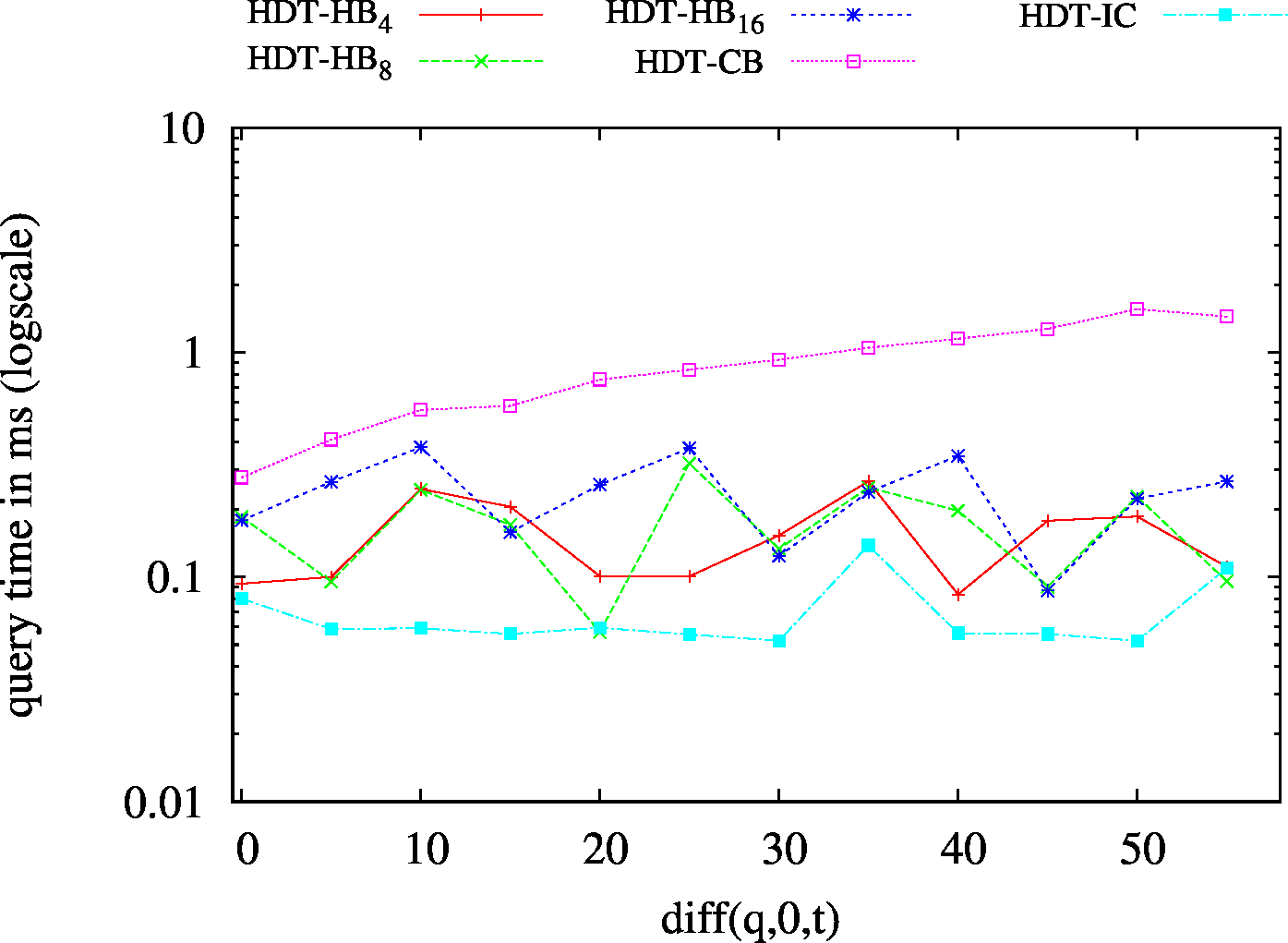
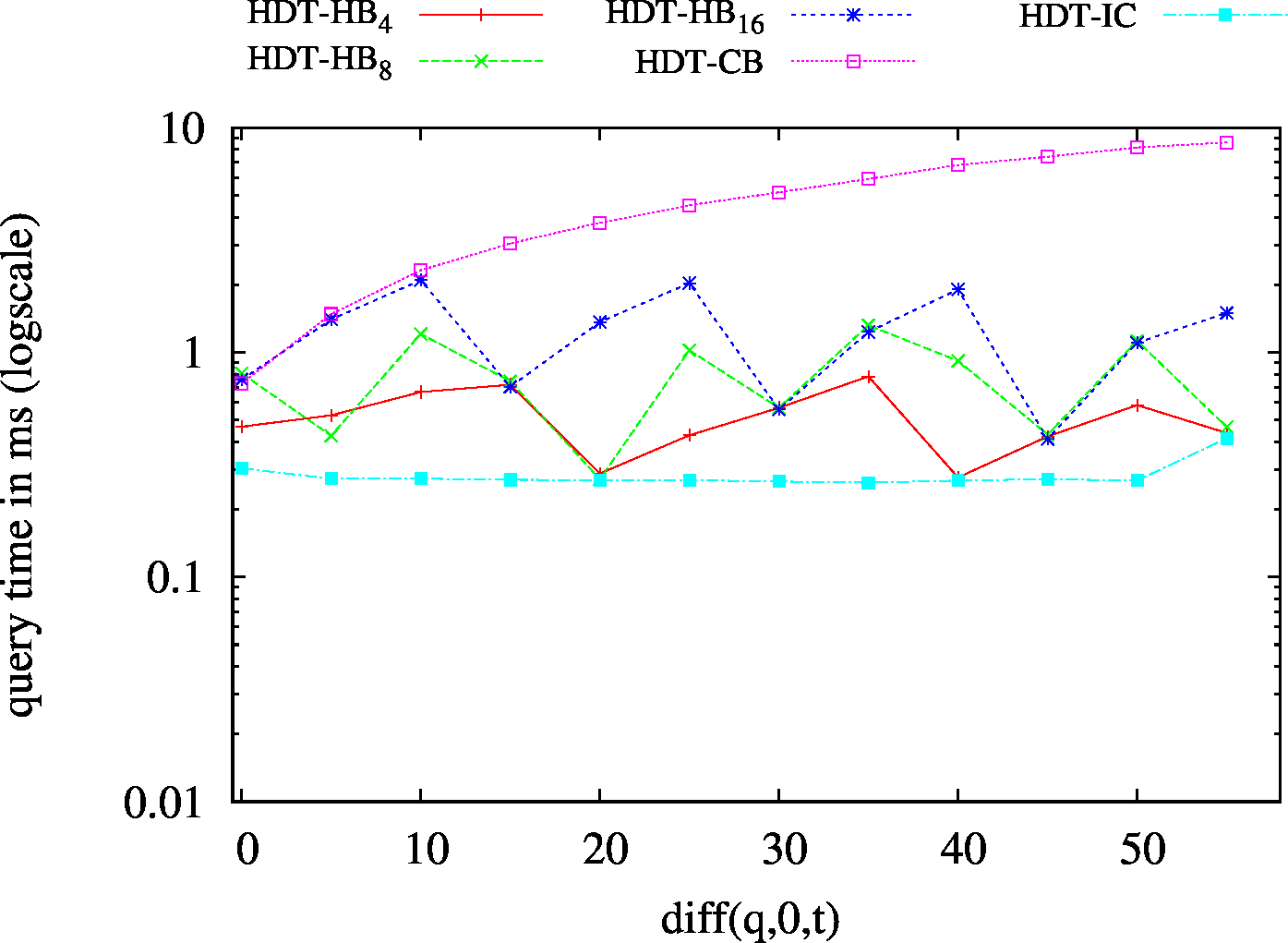
We also implemented and tested hybrid approaches:
Tests were performed on a computer with 2 x Intel Xeon E5-2650v2 @ 2.6 GHz (16 cores), RAM 171 GB, 4 HDDs in RAID 5 config. (2.7 TB netto storage), Ubuntu 14.04.5 LTS running on a VM with QEMU/KVM hypervisor. We report elapsed times for Jena in a warm scenario, given that it is based on disk whereas HDT performs on memory.
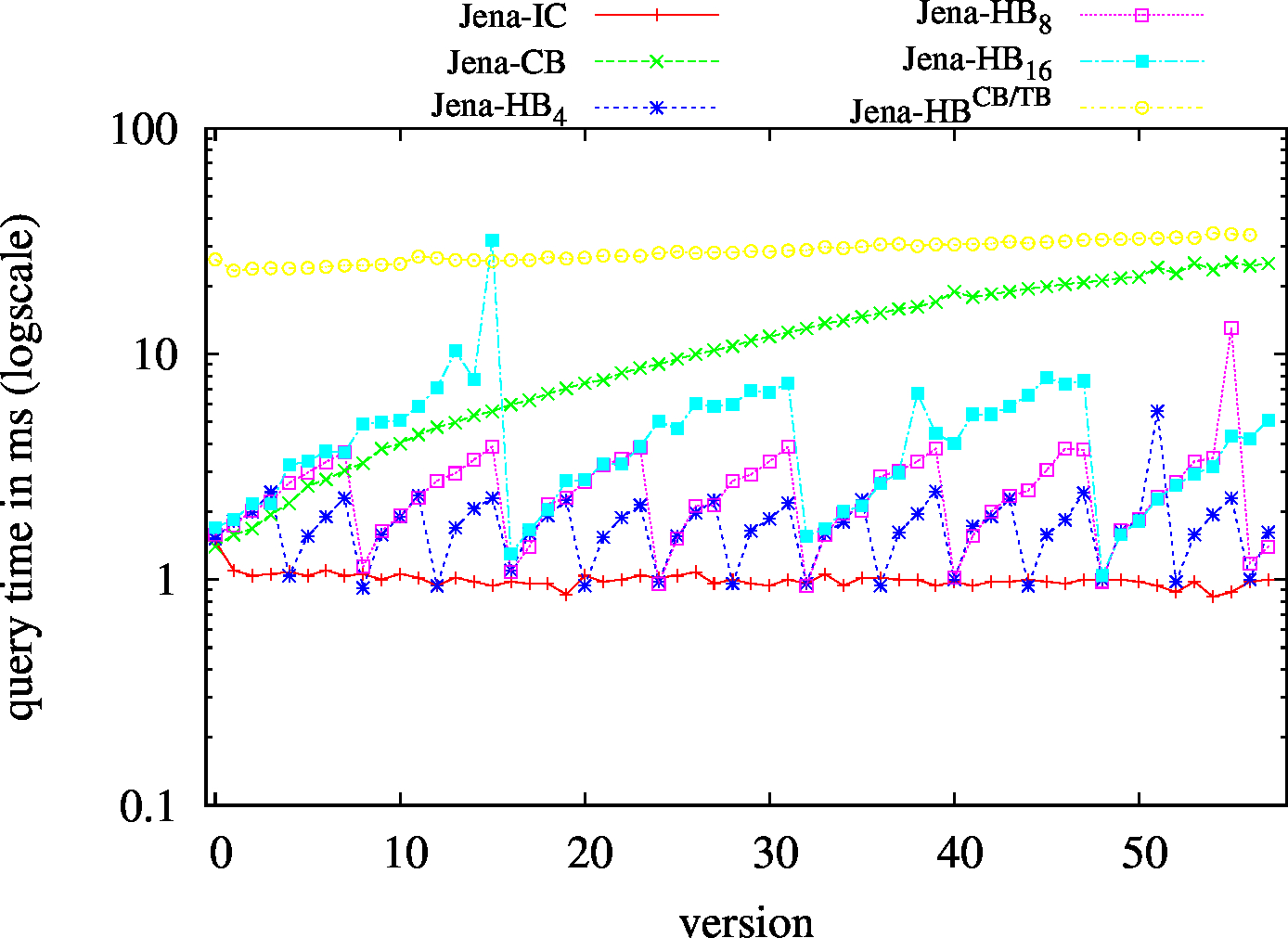
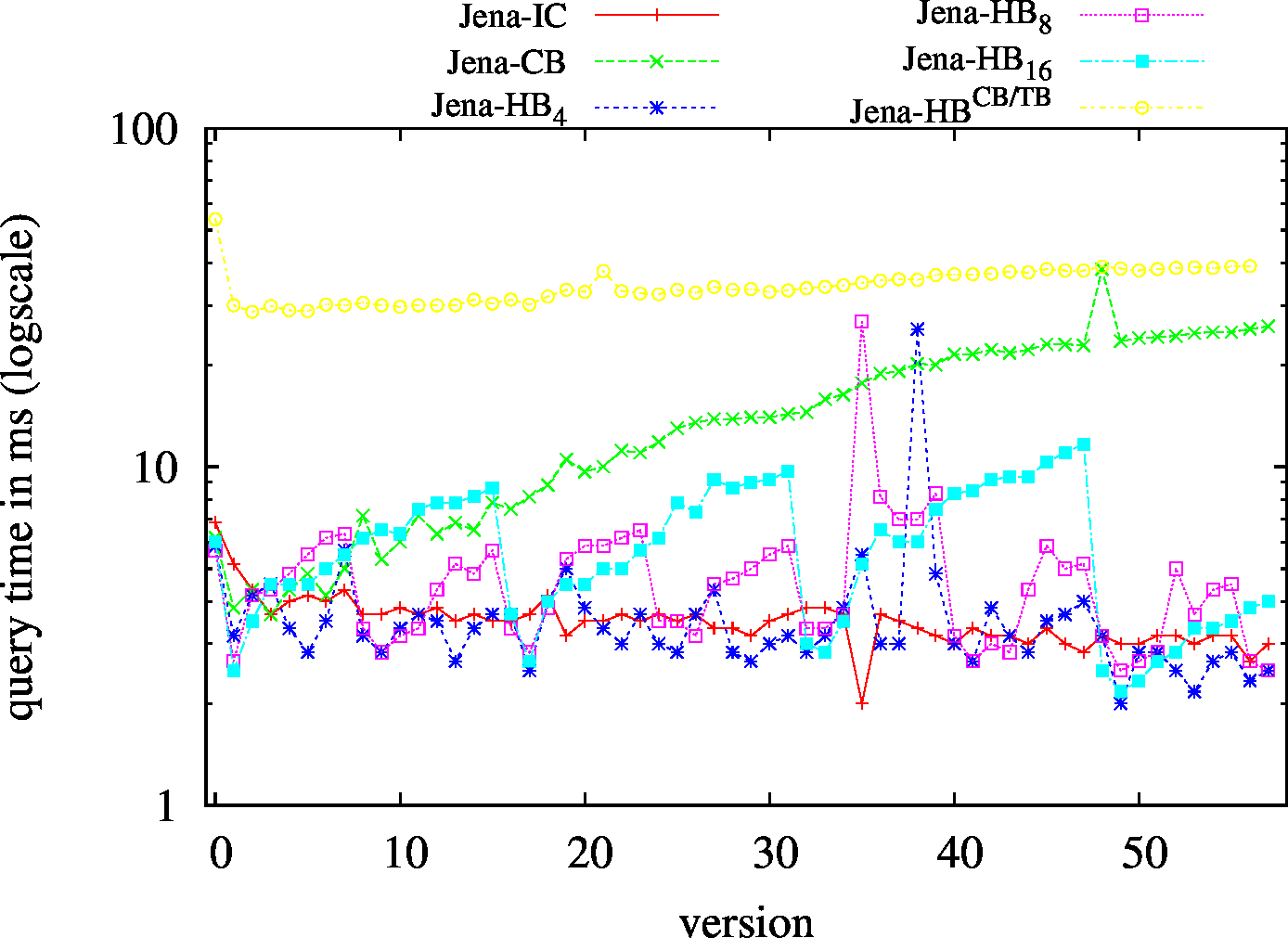
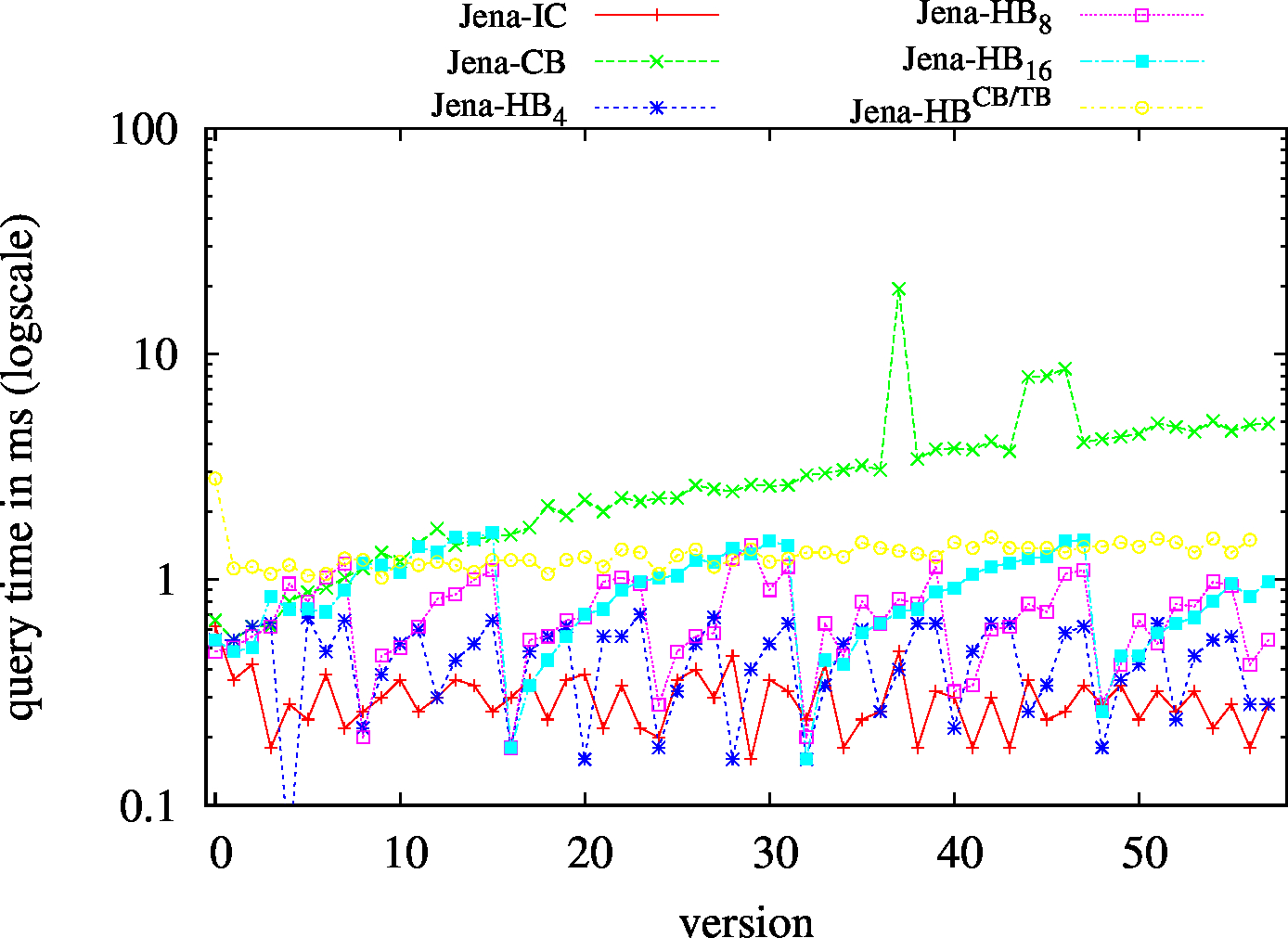
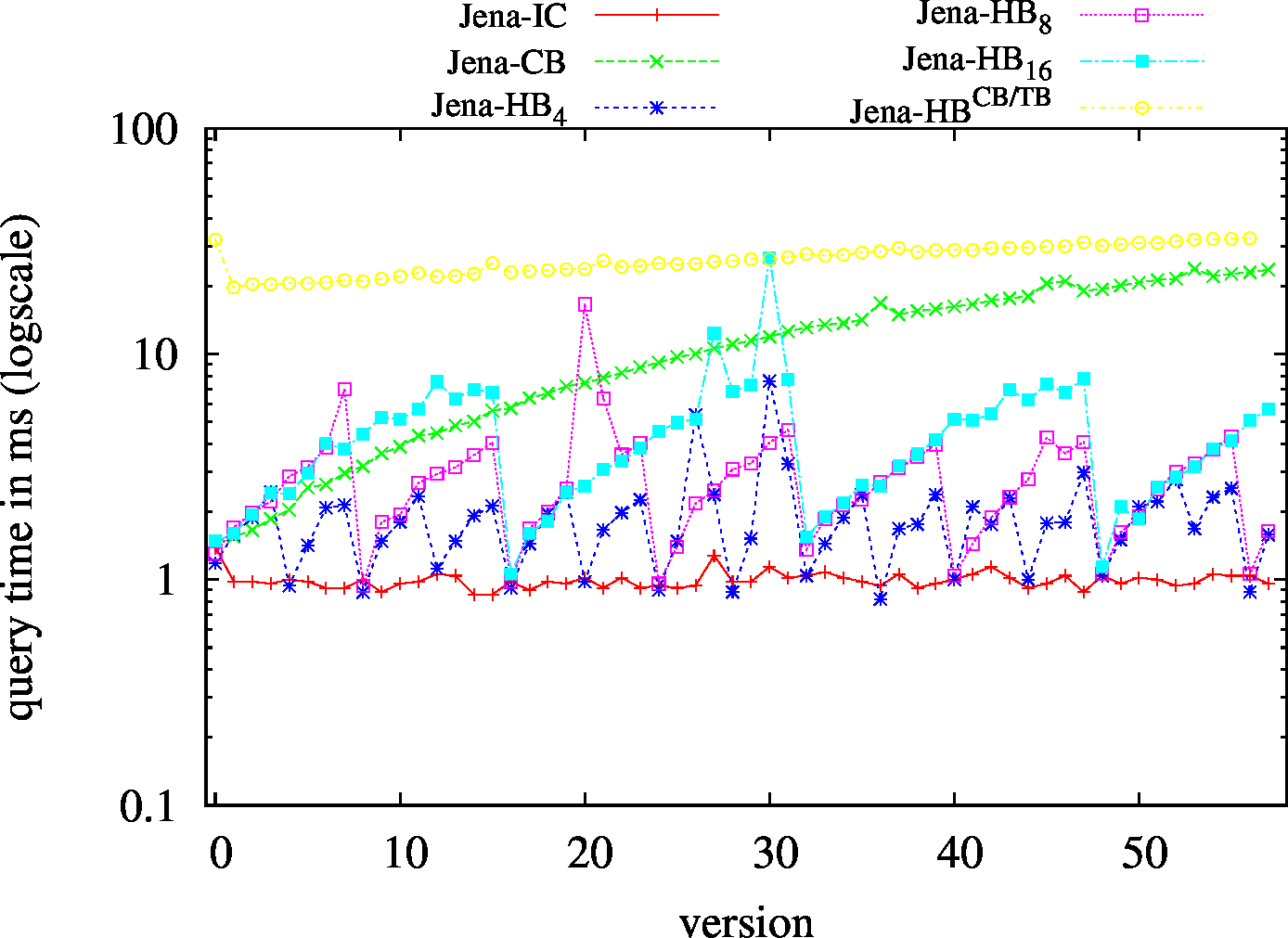
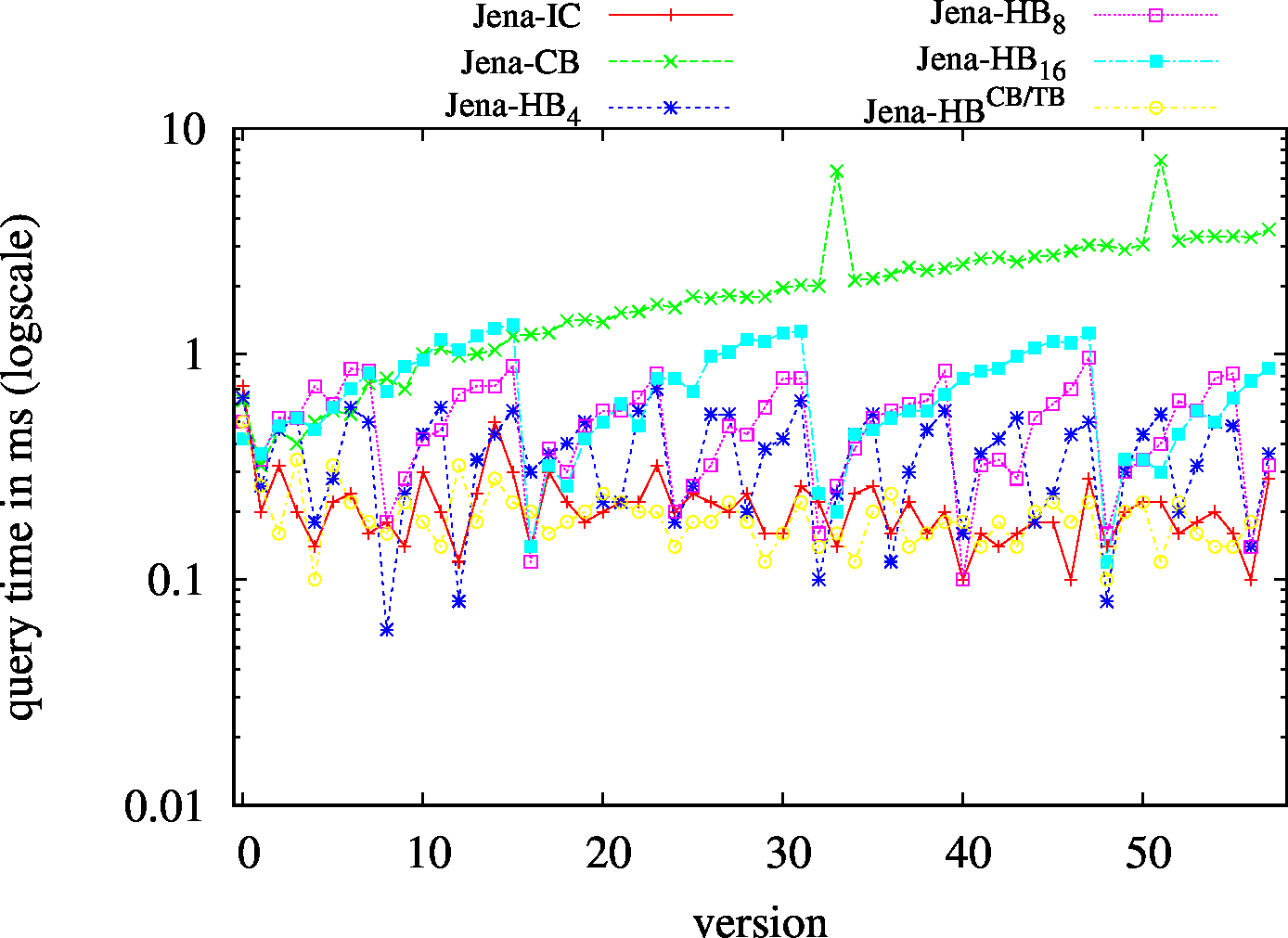
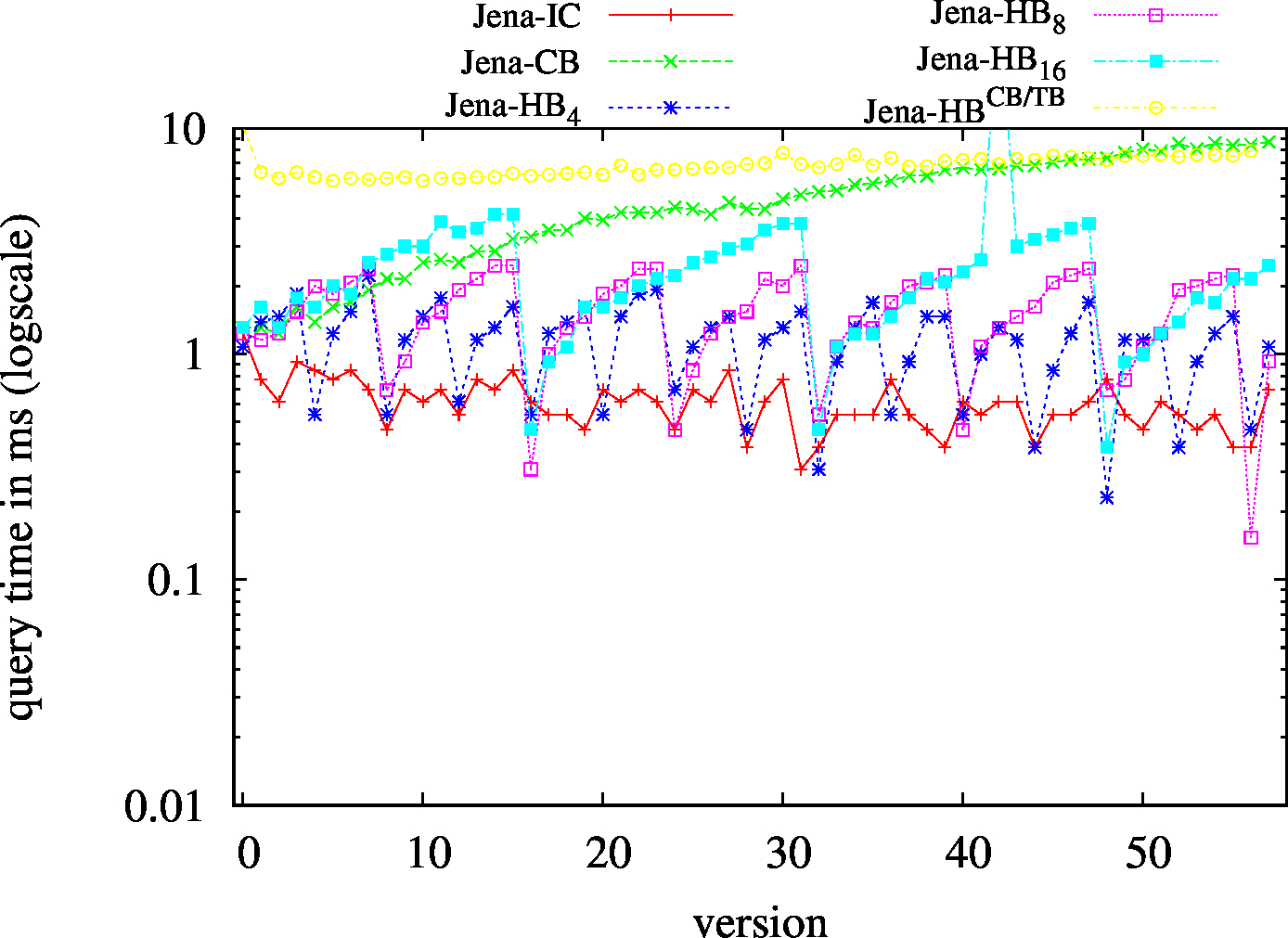
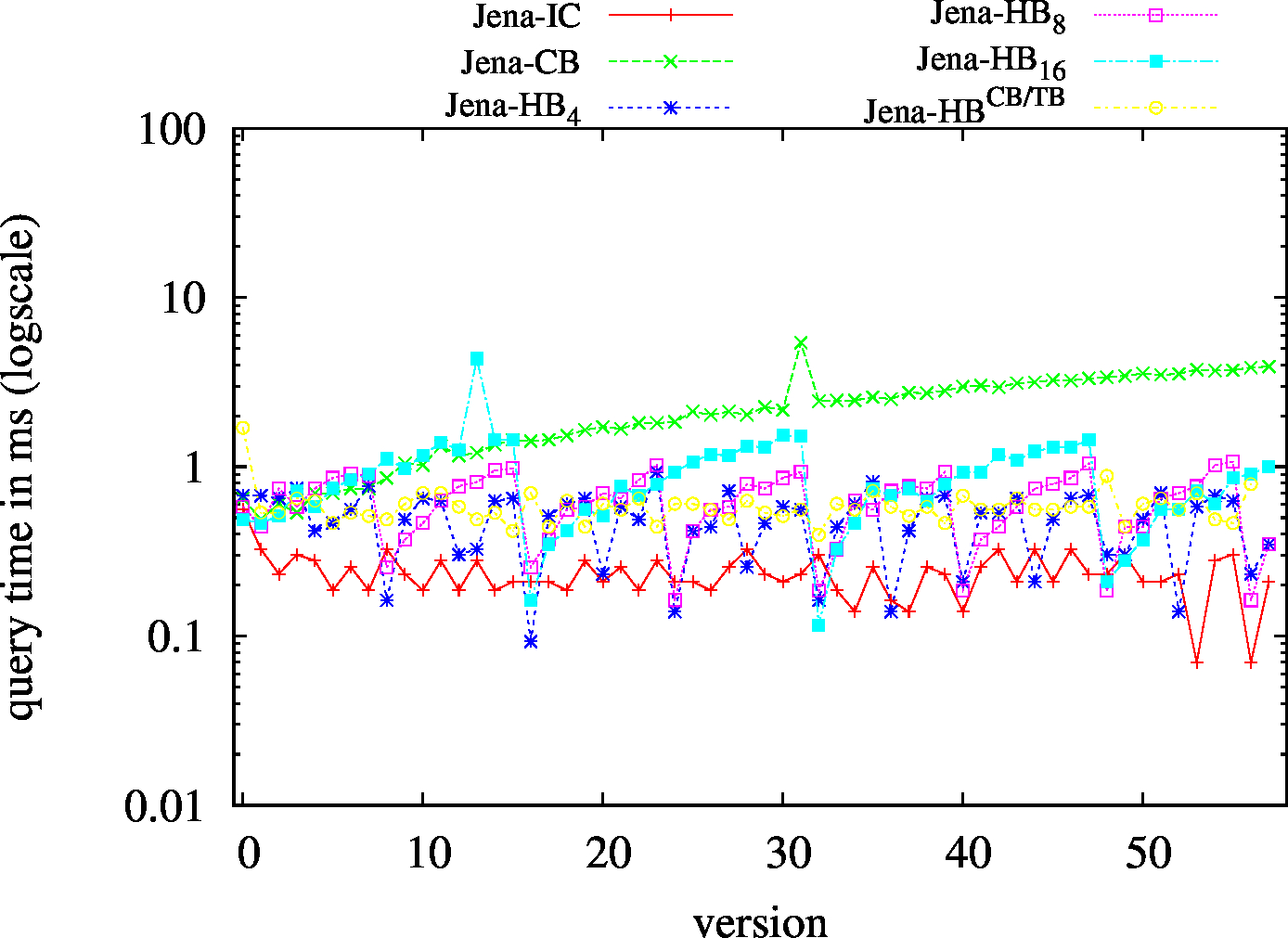
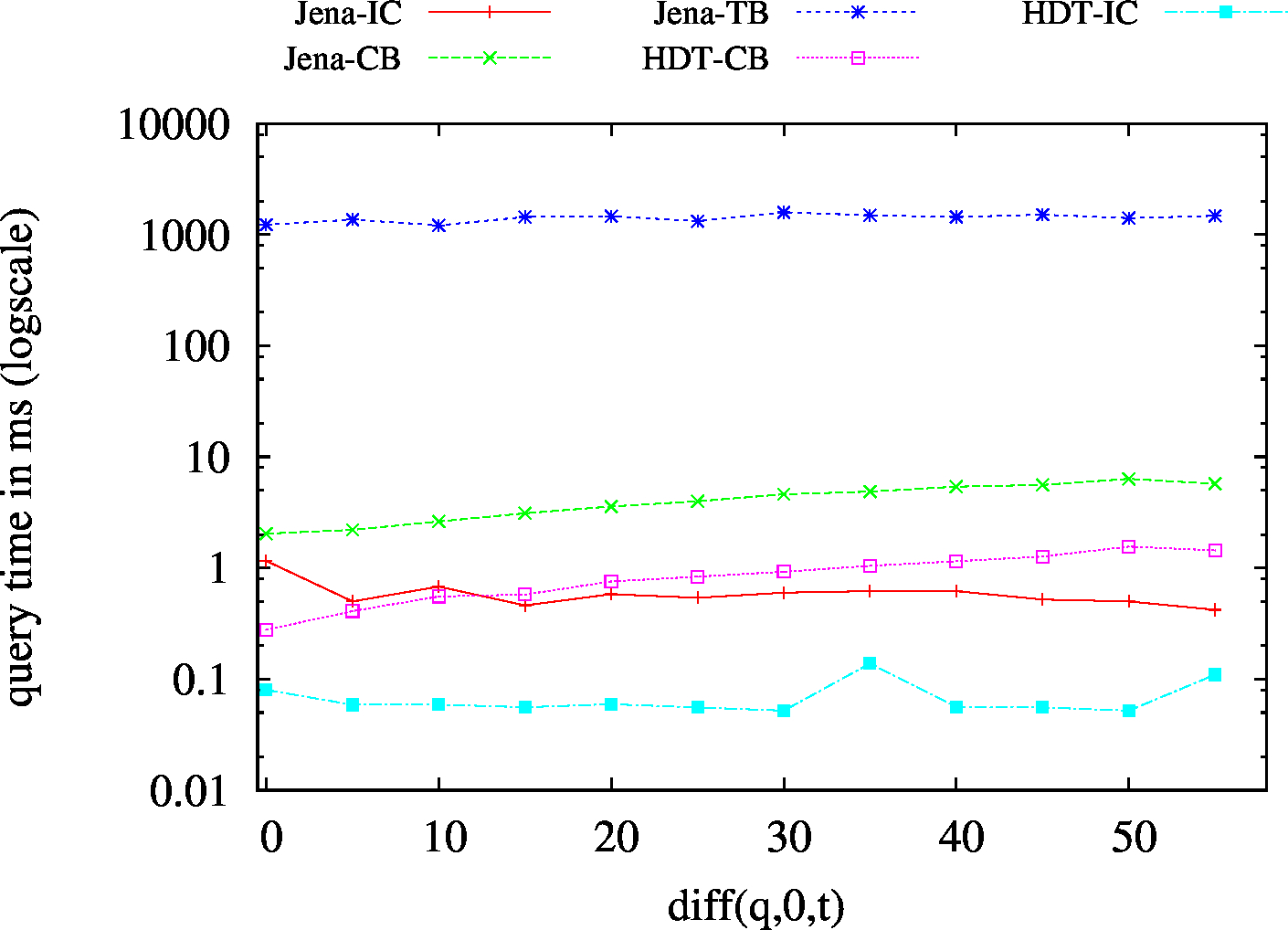
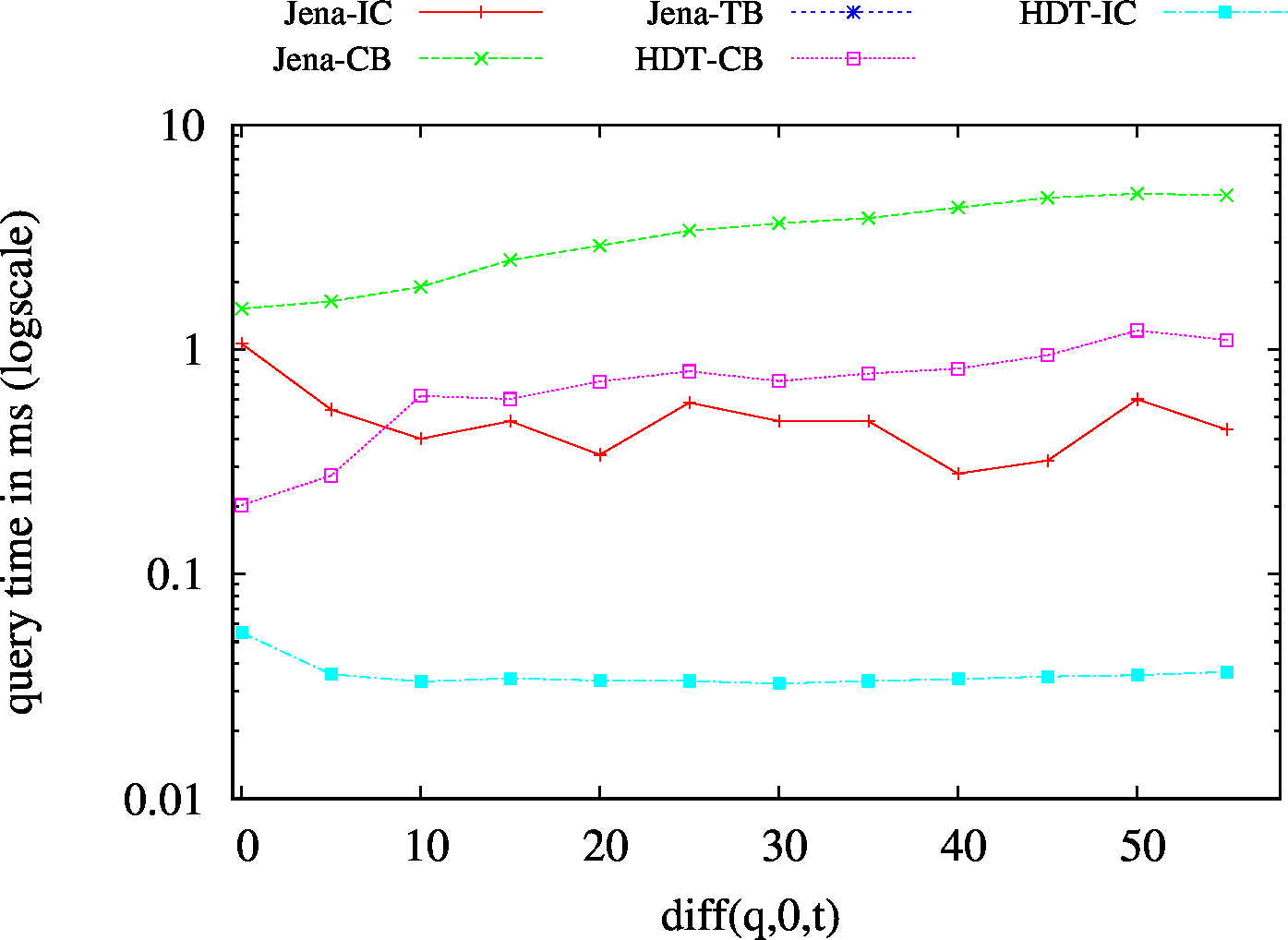
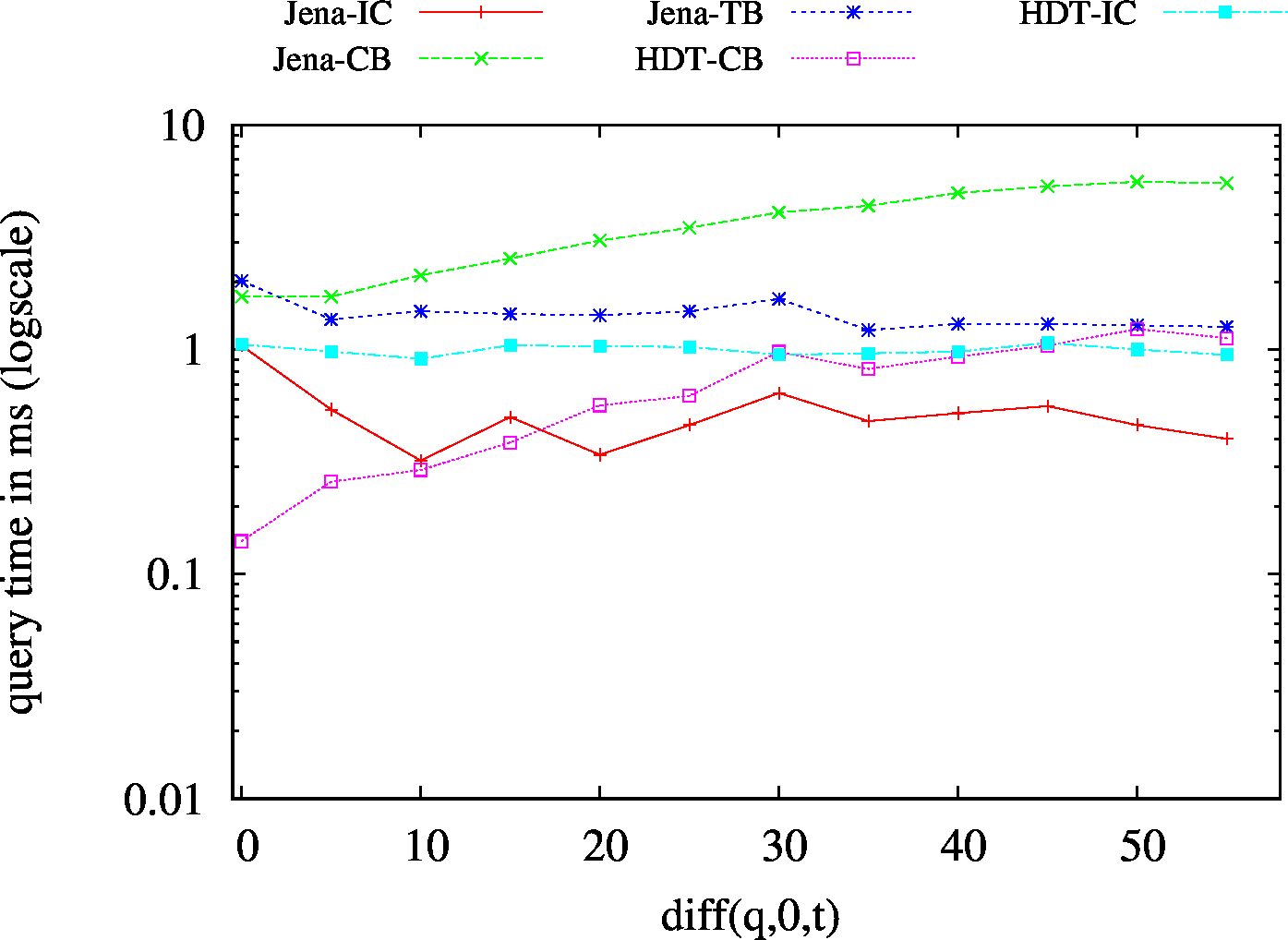
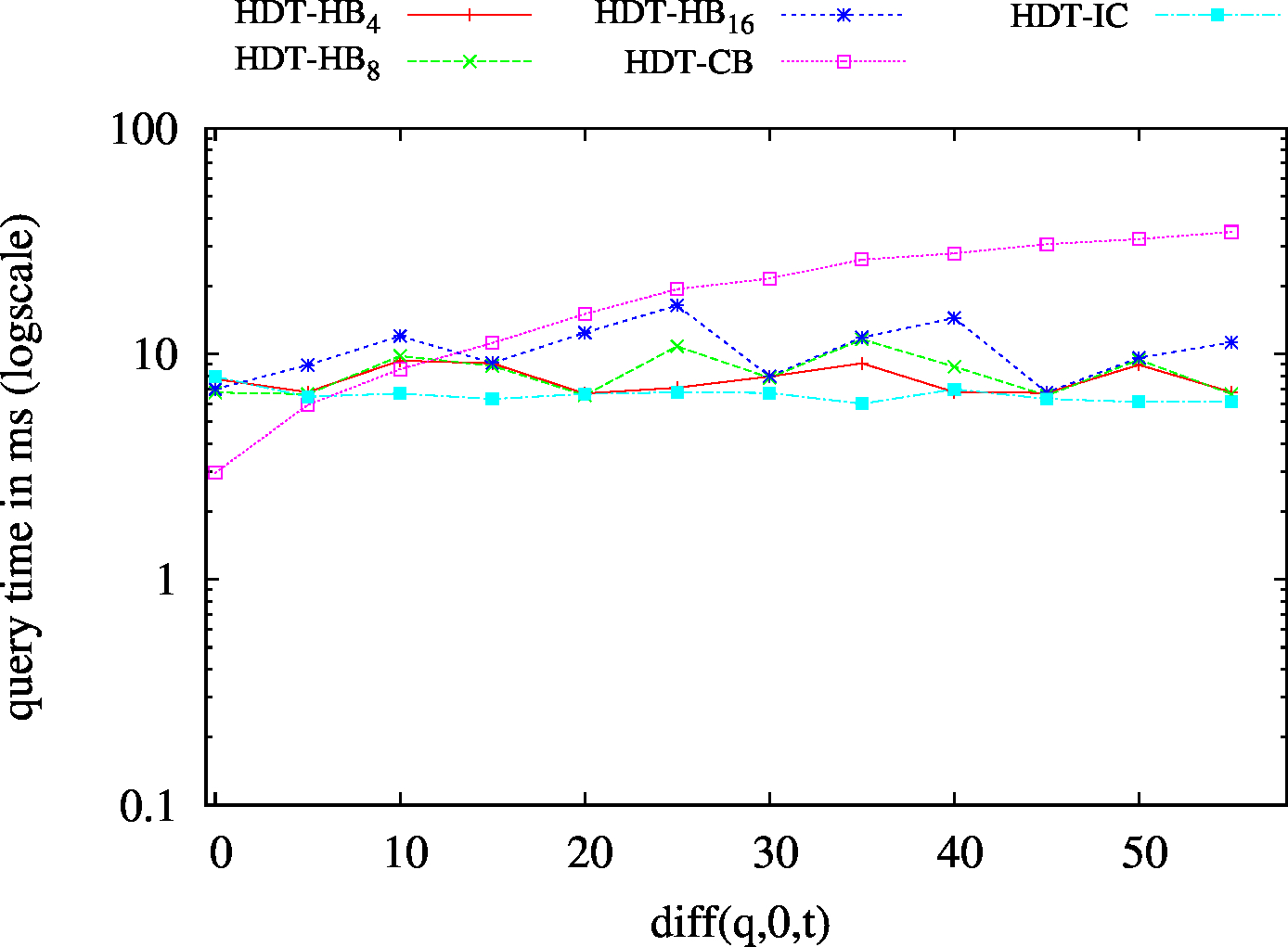
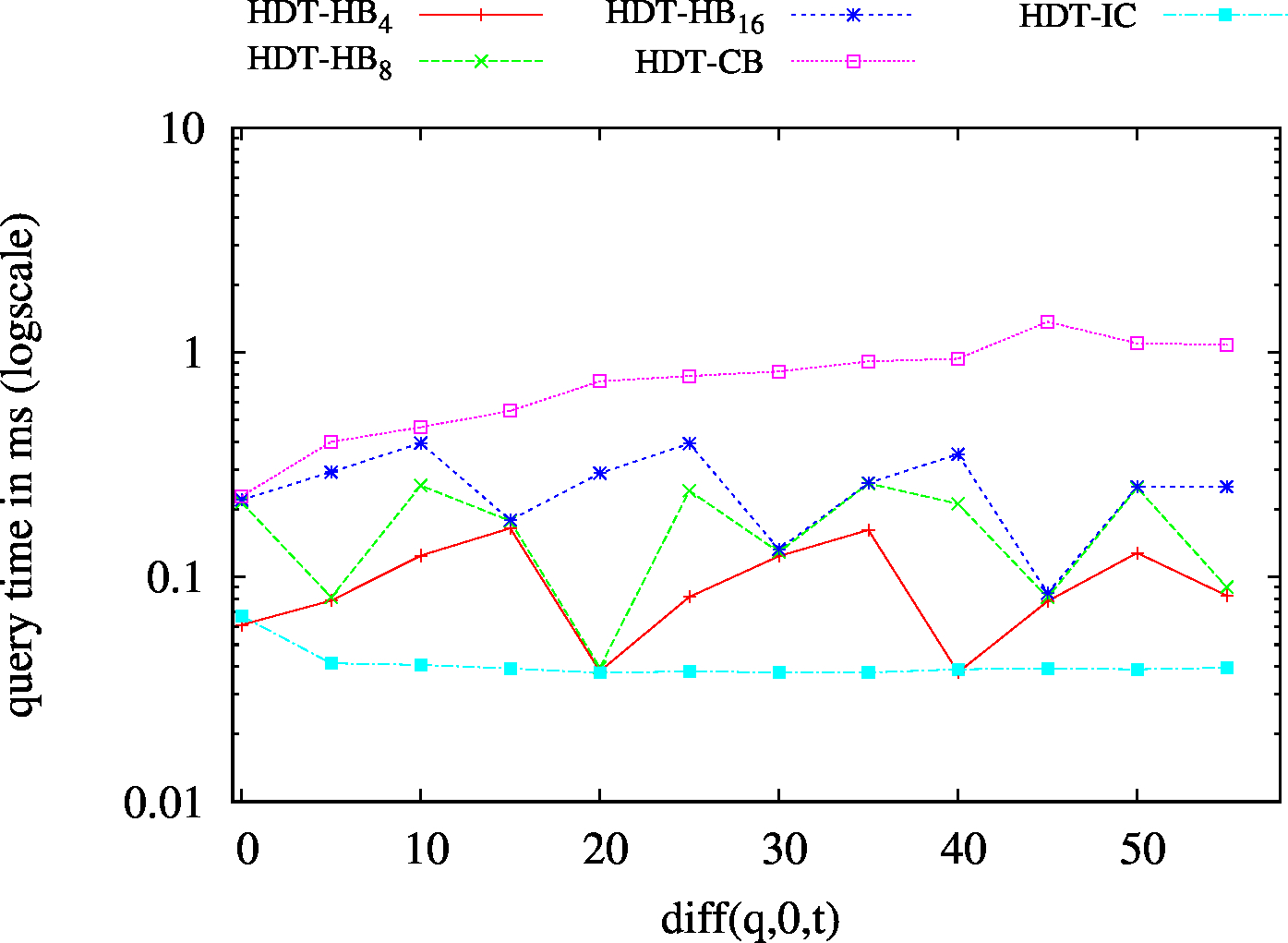
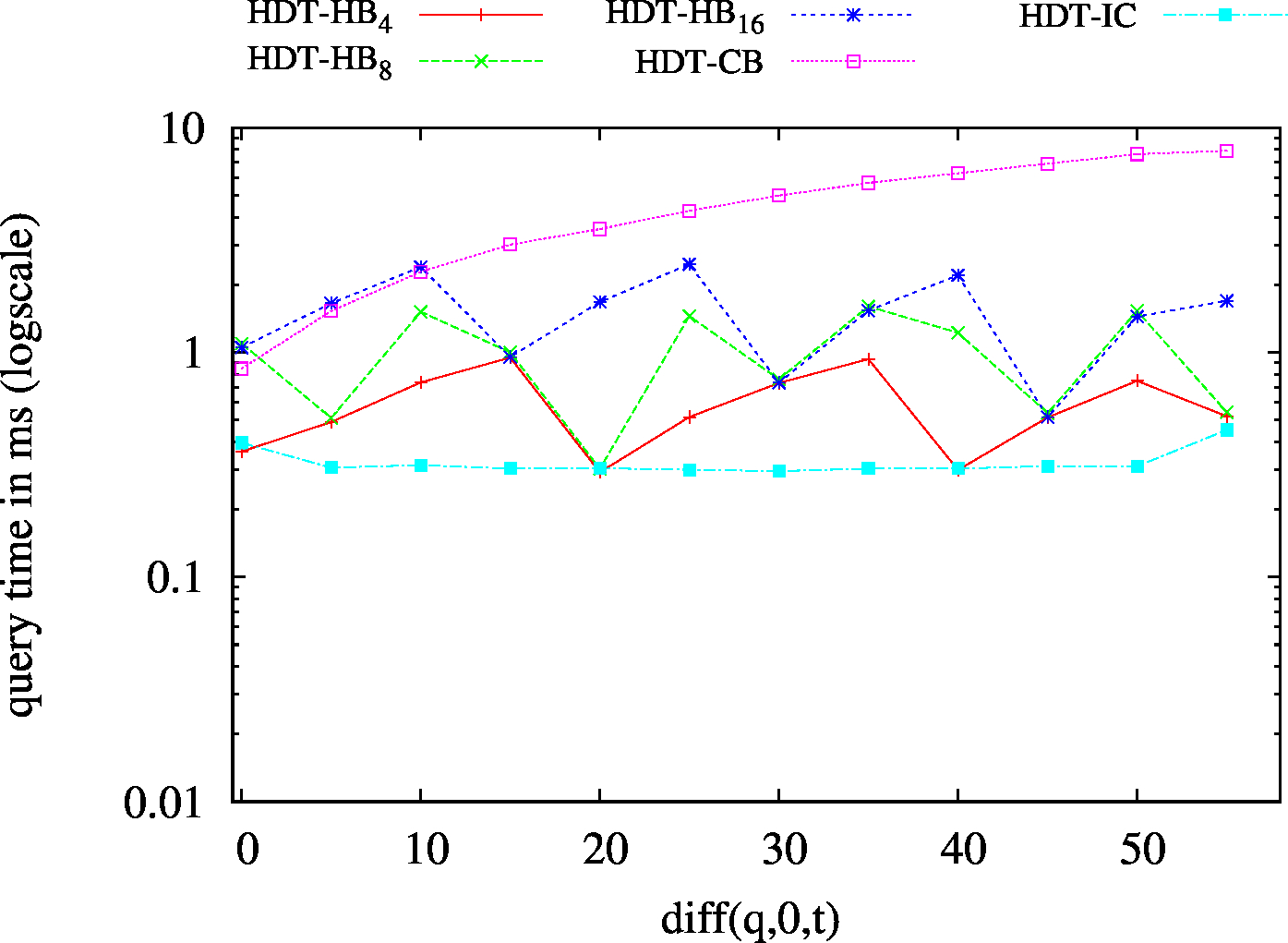
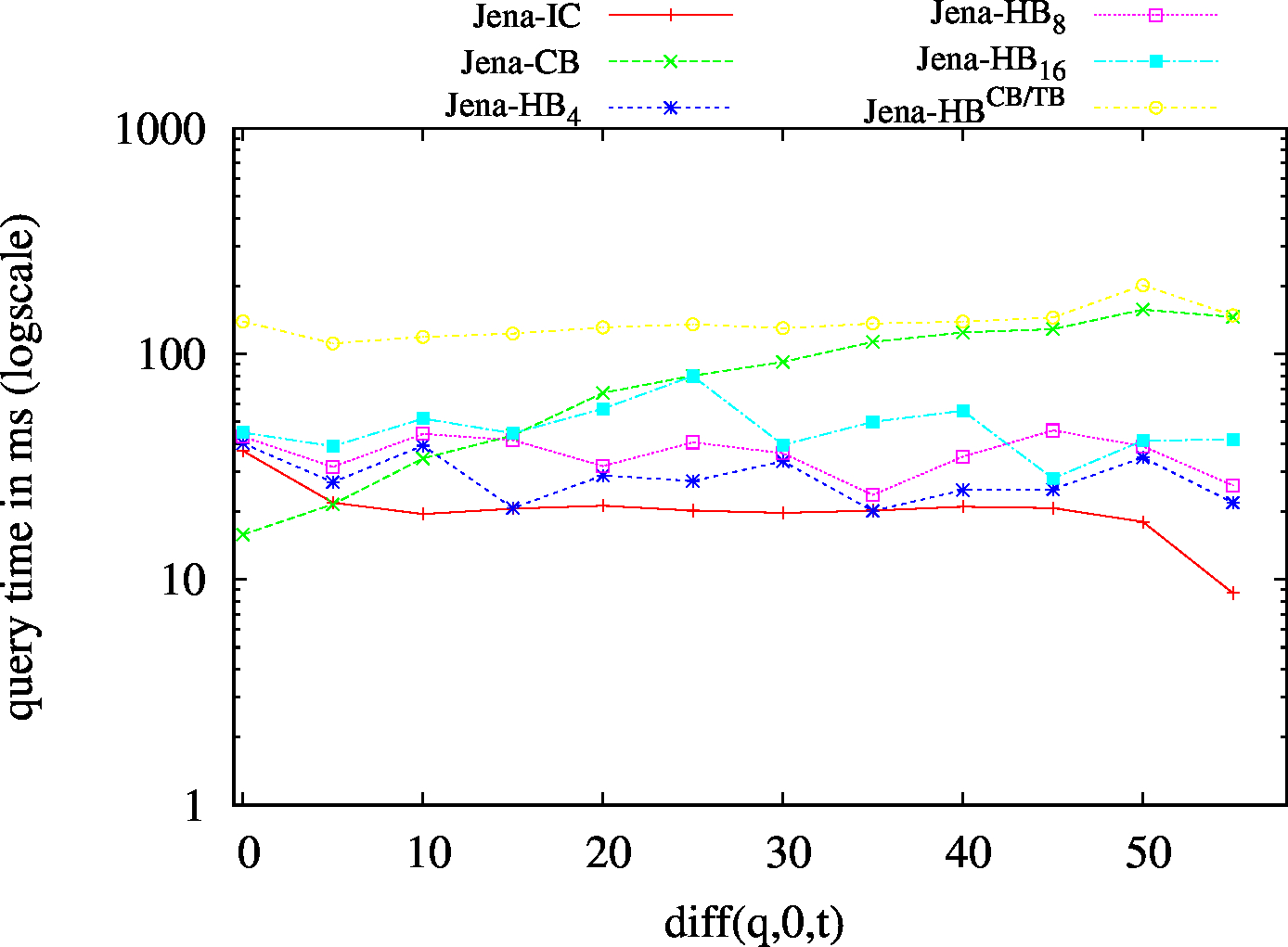
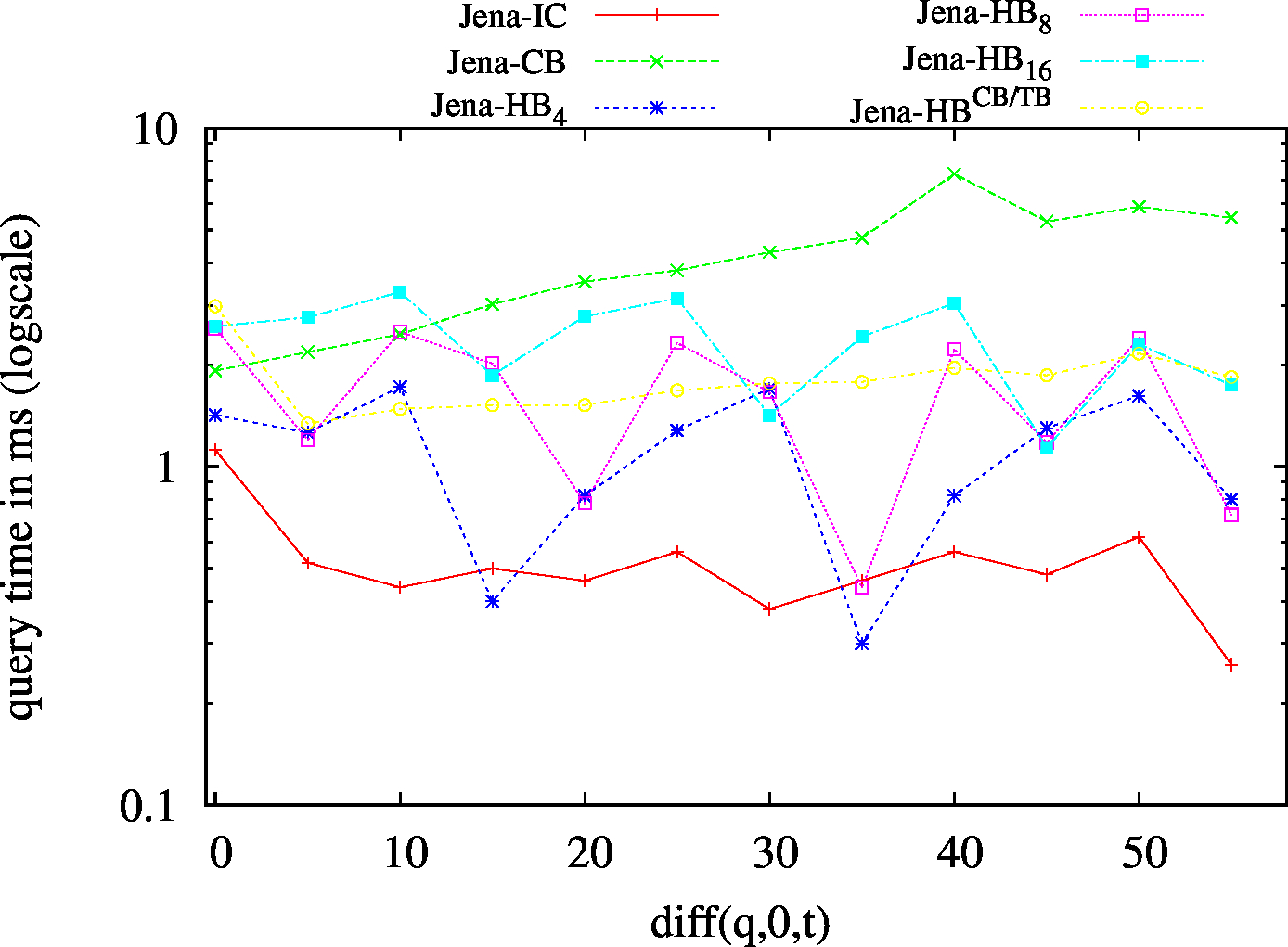
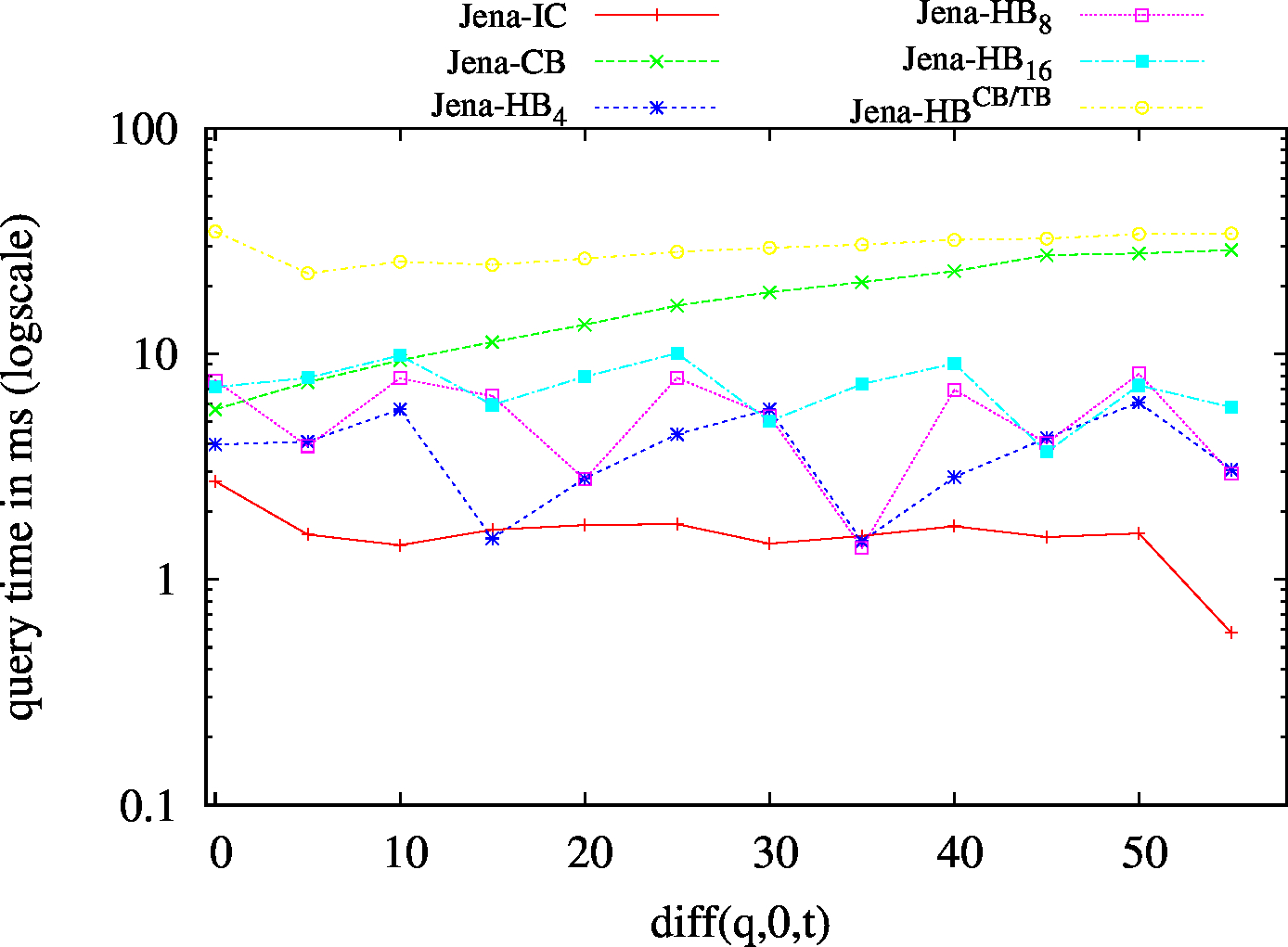
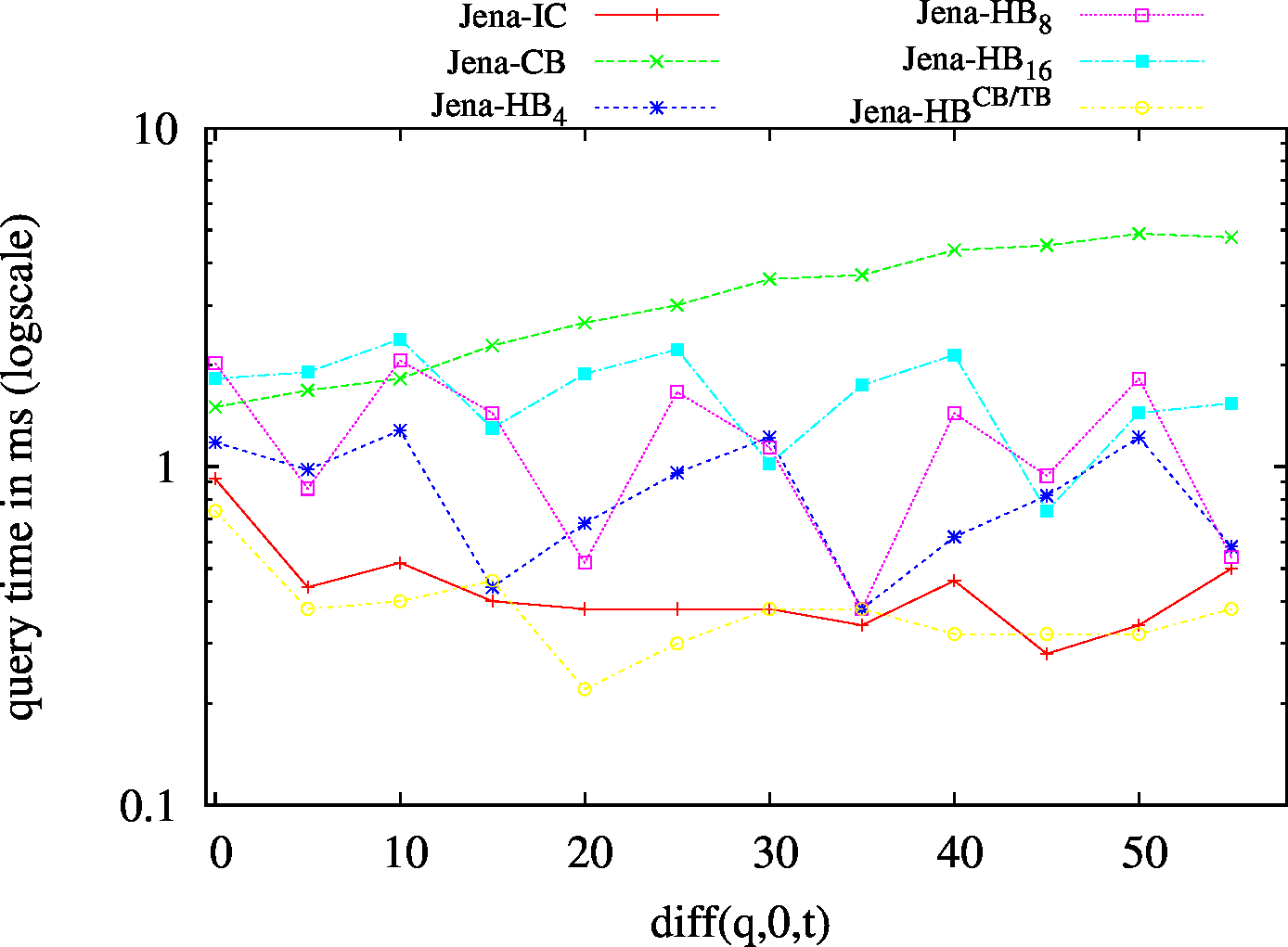
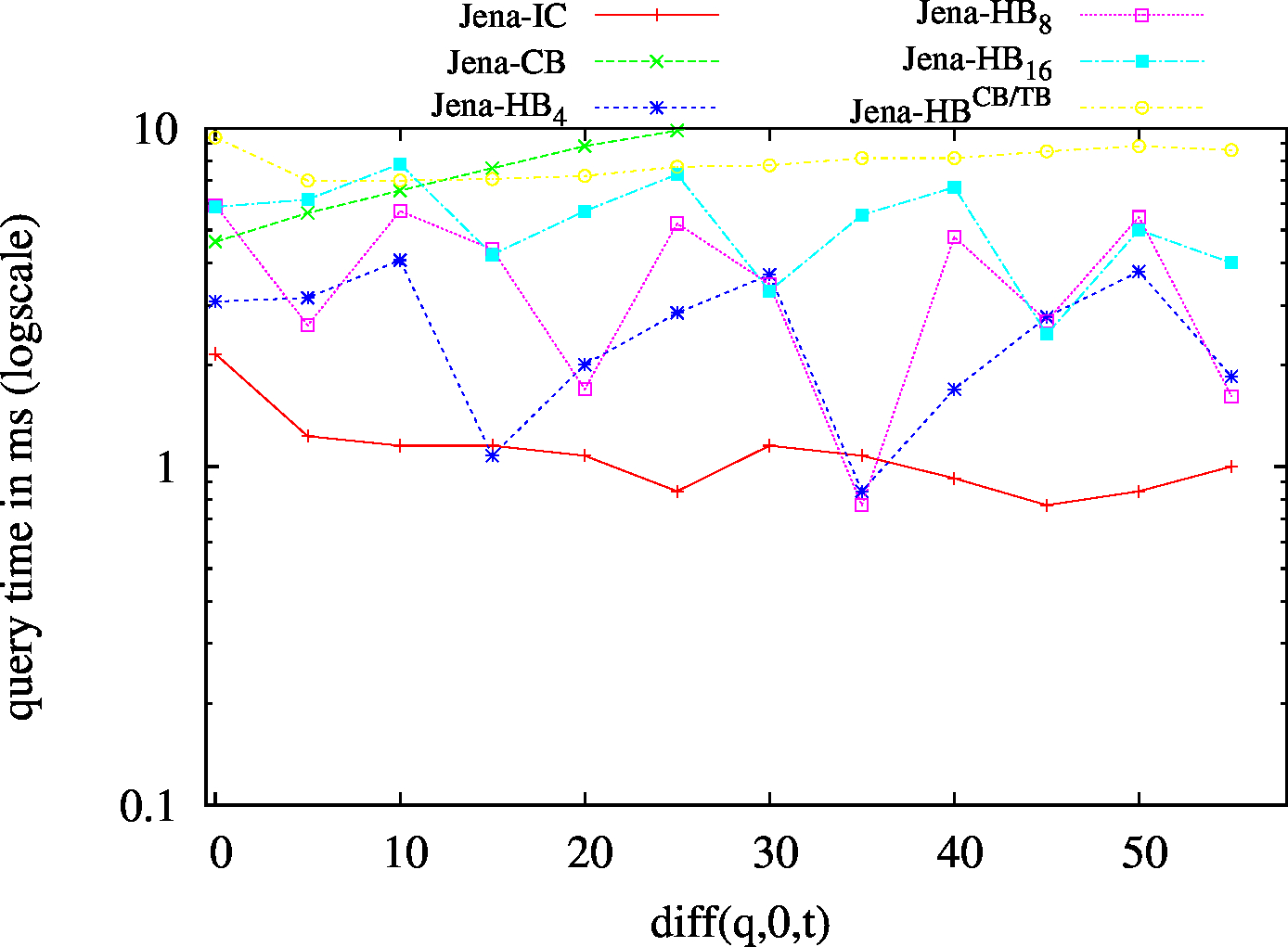
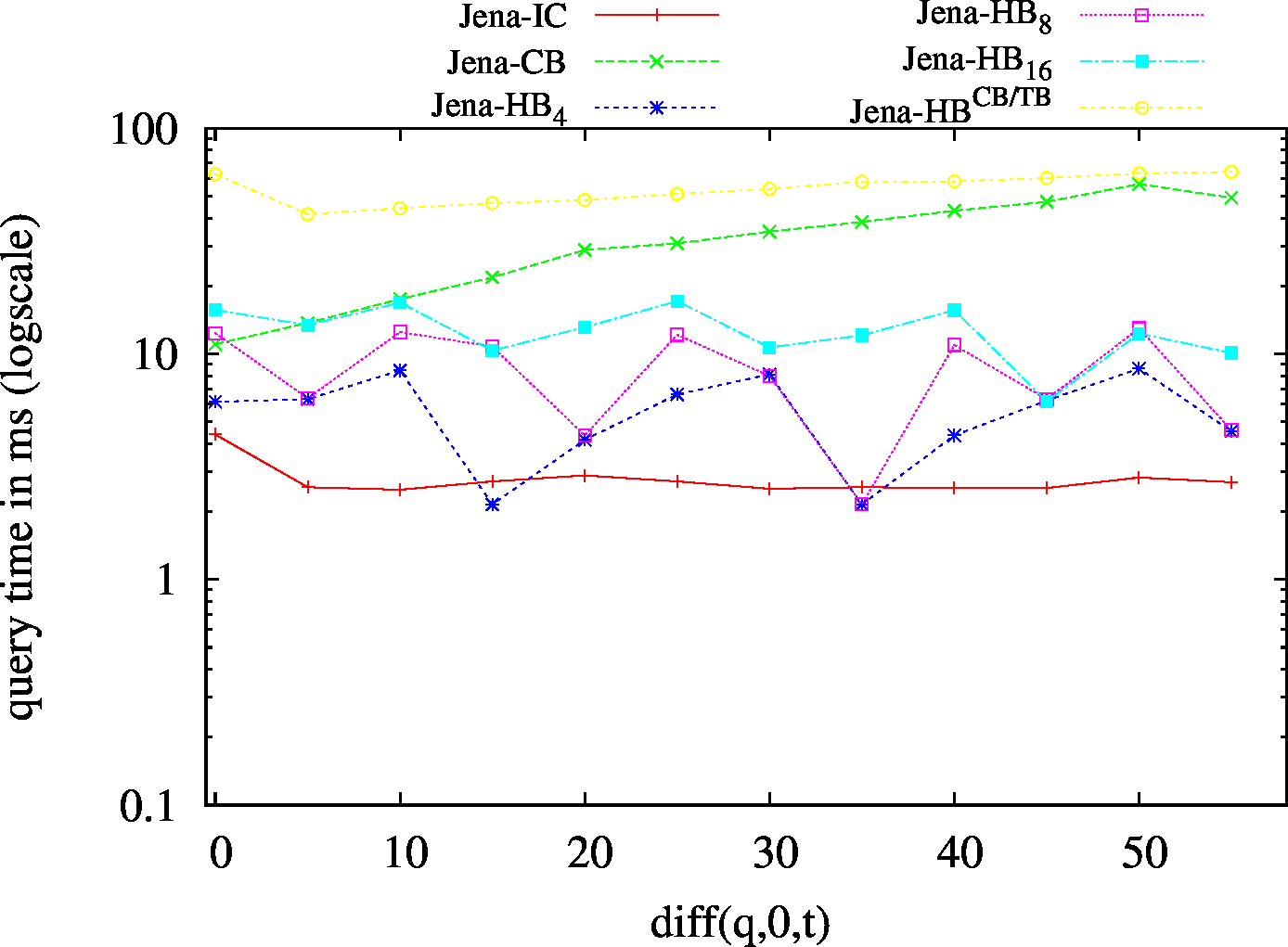
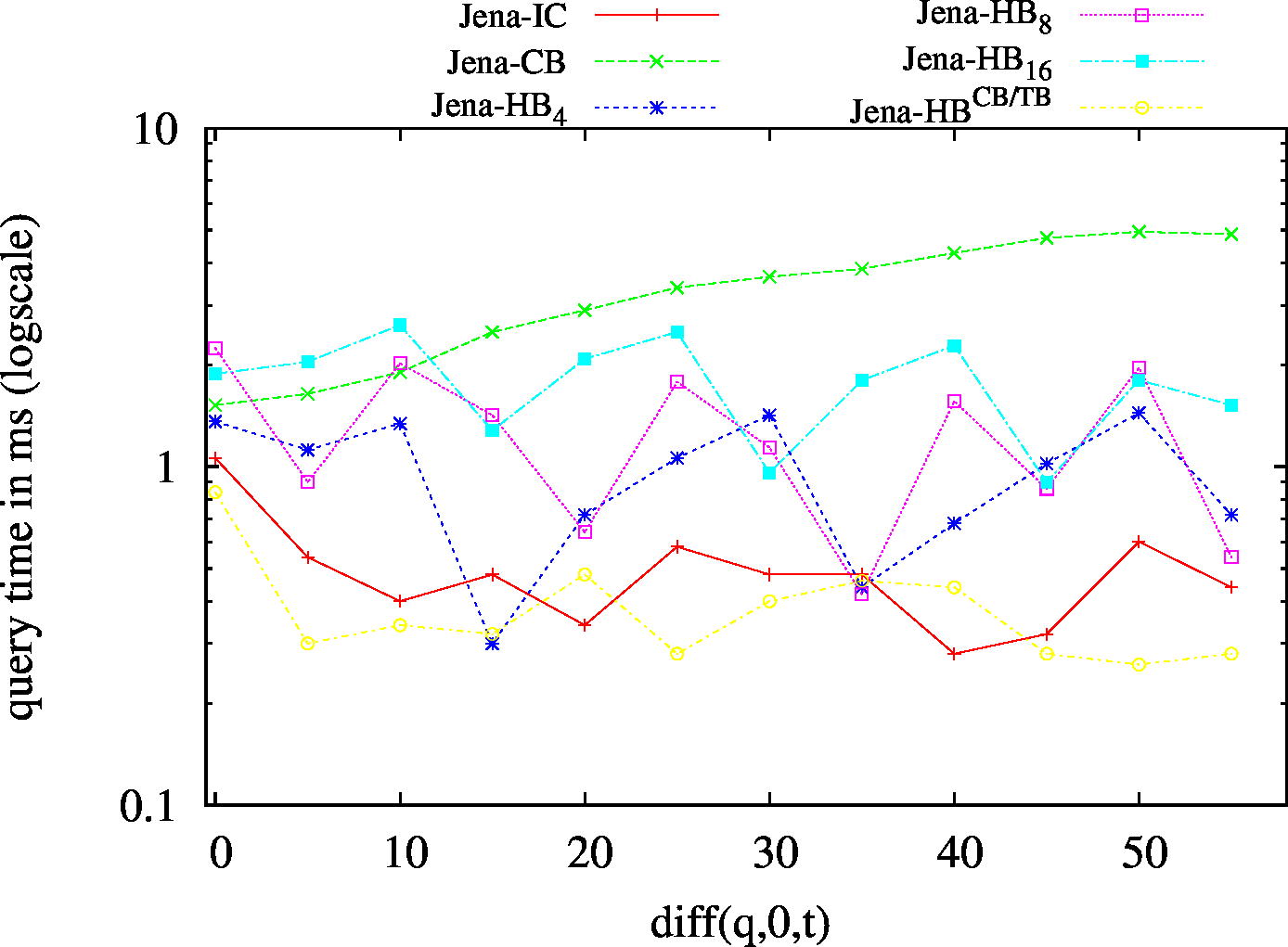
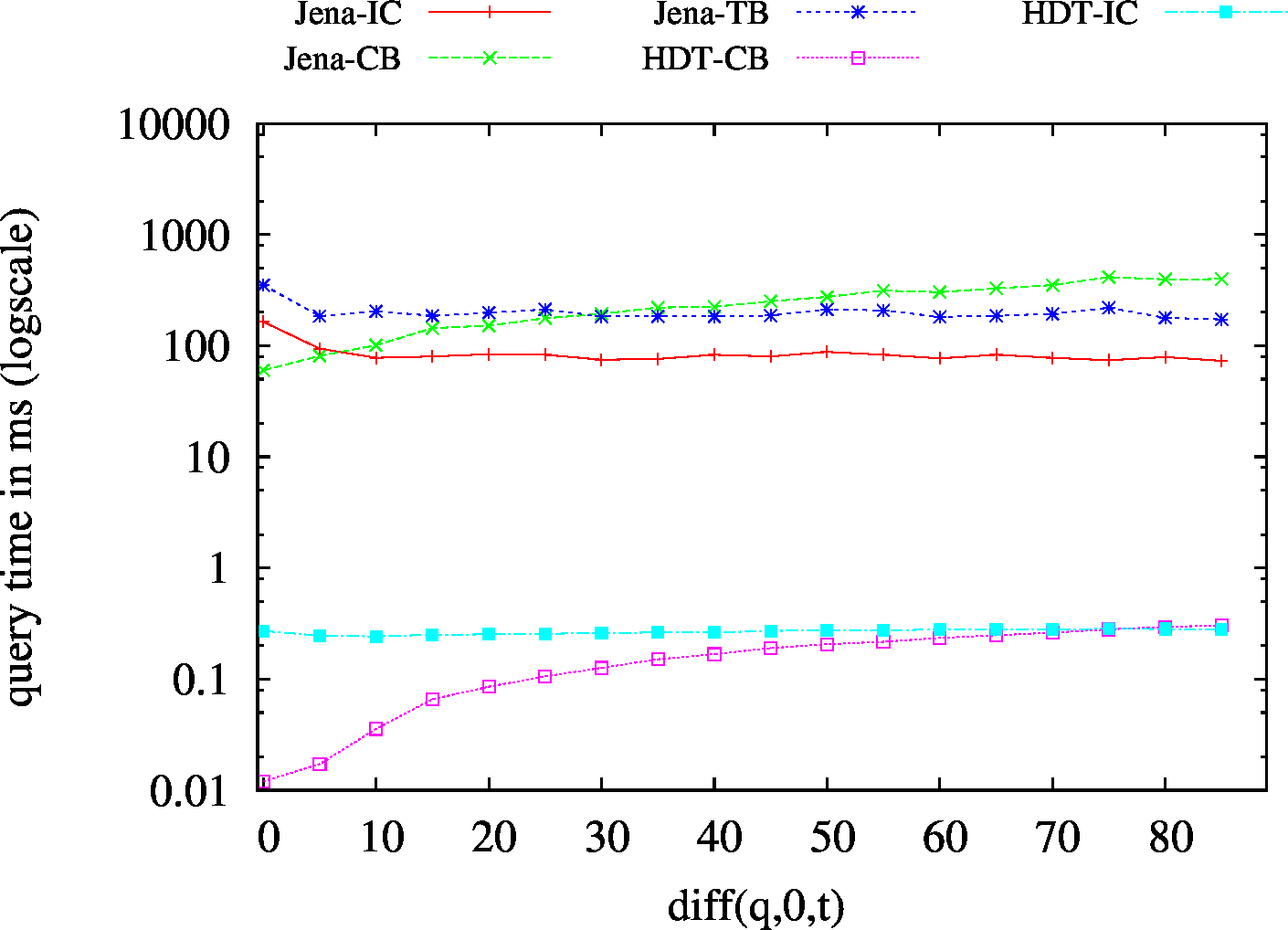
We report the required on-disk space for each dataset and system, as well as the query performance in BEAR-A and BEAR-B. See [1] for detailed comments of the results.
| Dataset | Raw (gzip) | Diff (gzip) | Jena TDB | HDT | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IC | CB | TB | Hybrid | IC | CB | Hybrid | ||||||||
| HBSIC/CB | HBMIC/CB | HBLIC/CB | HBTB/CB | HBSIC/CB | HBMIC/CB | HBLIC/CB | ||||||||
| BEAR-A | 23 GB | 14 GB | 230 GB | 138 GB | 83 GB | 163 GB | 152 GB | 143 GB | 353 GB | 48 GB | 28 GB | 34 GB | 31 GB | 29 GB |
| BEAR-B-instant | 12 GB | 0.16 GB | 158 GB | 7.4 GB | - | 9.7 GB | 7.7 GB | 7.4 GB | 0.1 GB | 63 GB | 0.33 GB | 1.4 GB | 0.46 GB | 0.36 GB |
| BEAR-B-hour | 475 MB | 10 MB | 6238 MB | 479 MB | 3679 MB | 662 MB | 563 MB | 529 MB | 58 MB | 2229 MB | 35 MB | 103 MB | 69 MB | 52 MB |
| BEAR-B-day | 37 MB | 1 MB | 421 MB | 44 MB | 24 MB | 137 MB | 90 MB | 65 MB | 23 MB | 149 MB | 7 MB | 43 MB | 25 MB | 15 MB |
| BEAR-C | 243 MB | 205 MB | 2151 MB | 2271 MB | 2012 MB | 2356 MB | 2286 MB | 2310 MB | 3735 MB | 421 MB | 439 MB | 458 MB | 444 MB | 448 MB |
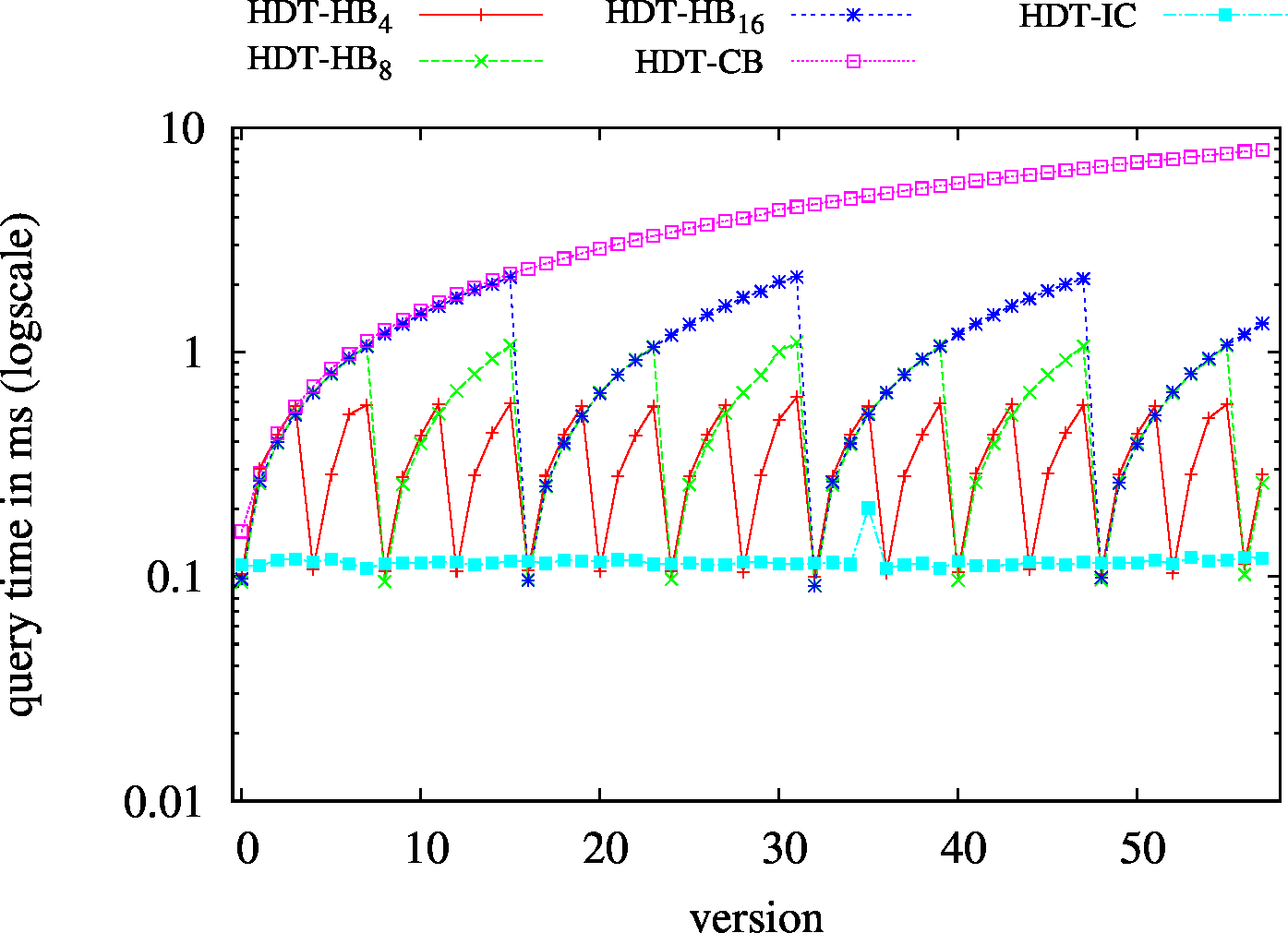
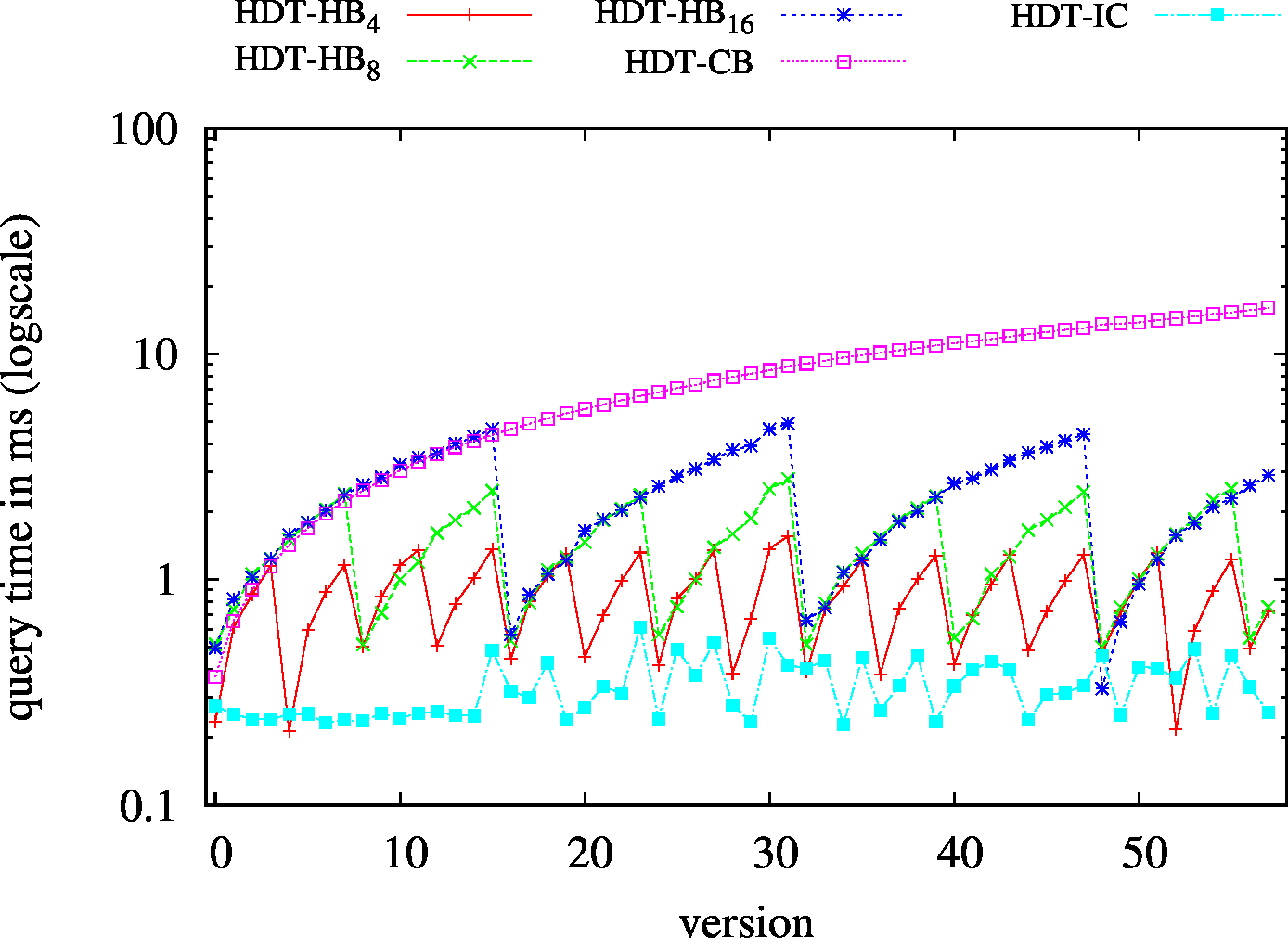
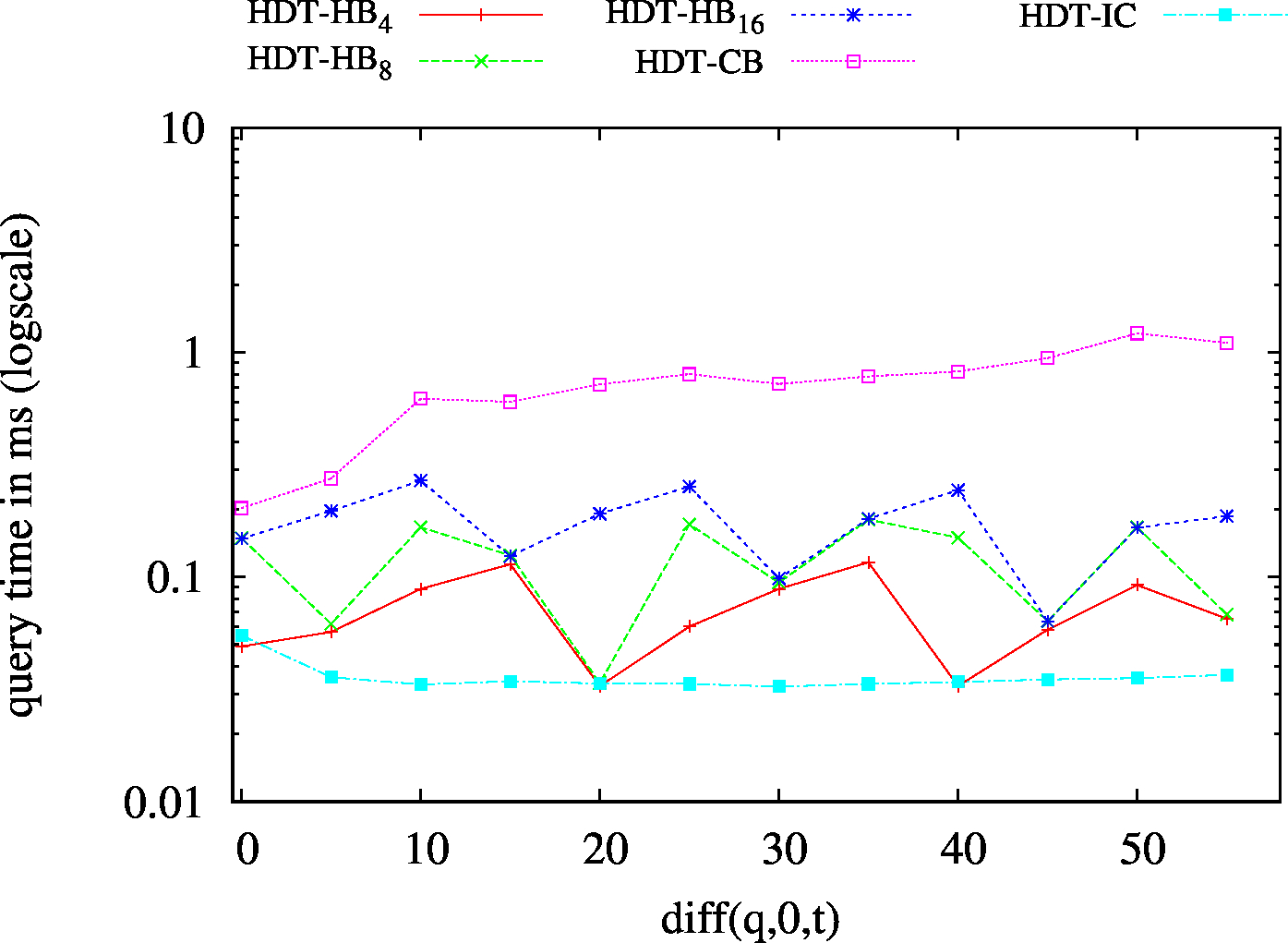
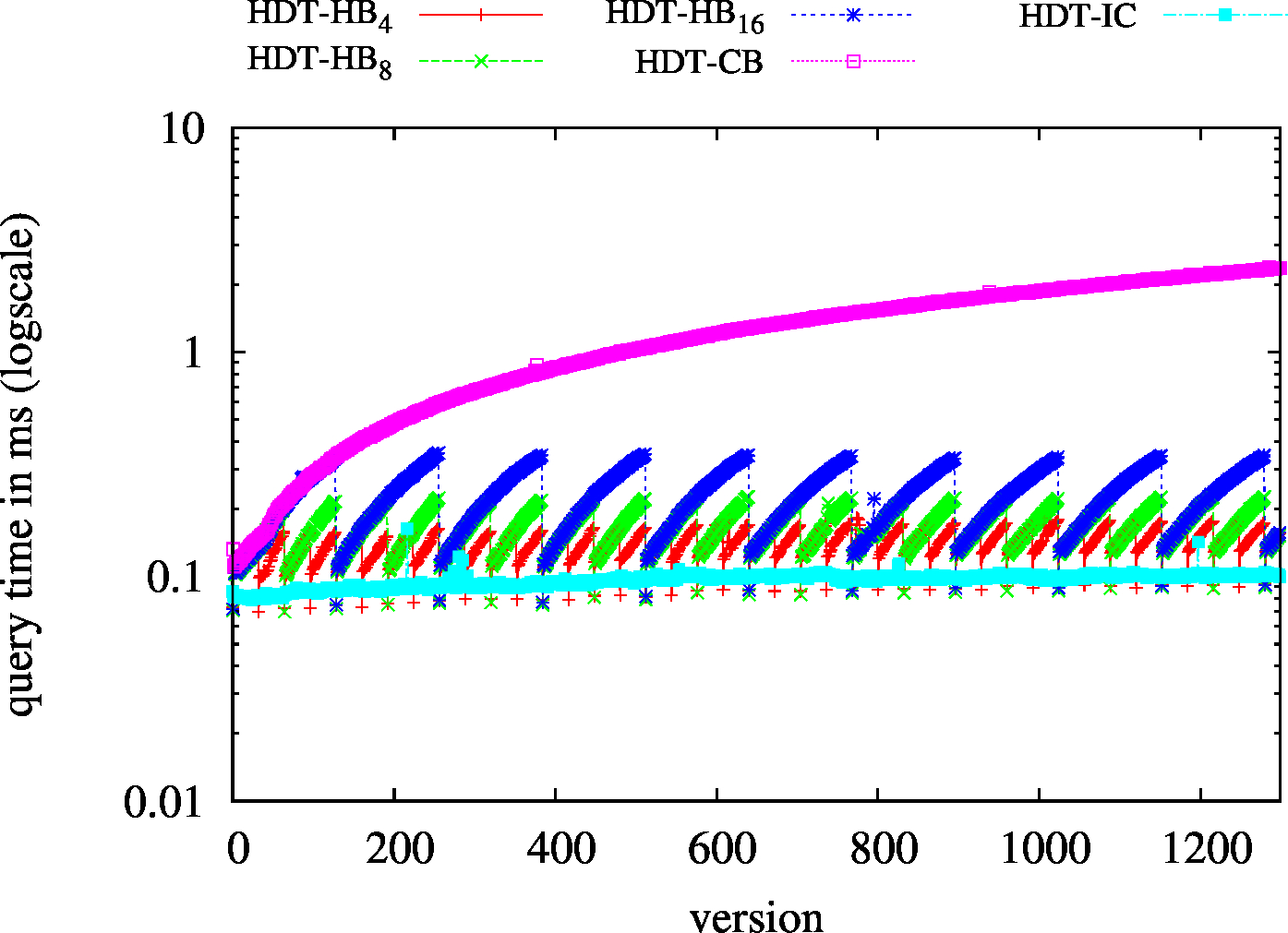
| S?? - Low Cardinality | S?? - High Cardinality |
|---|---|
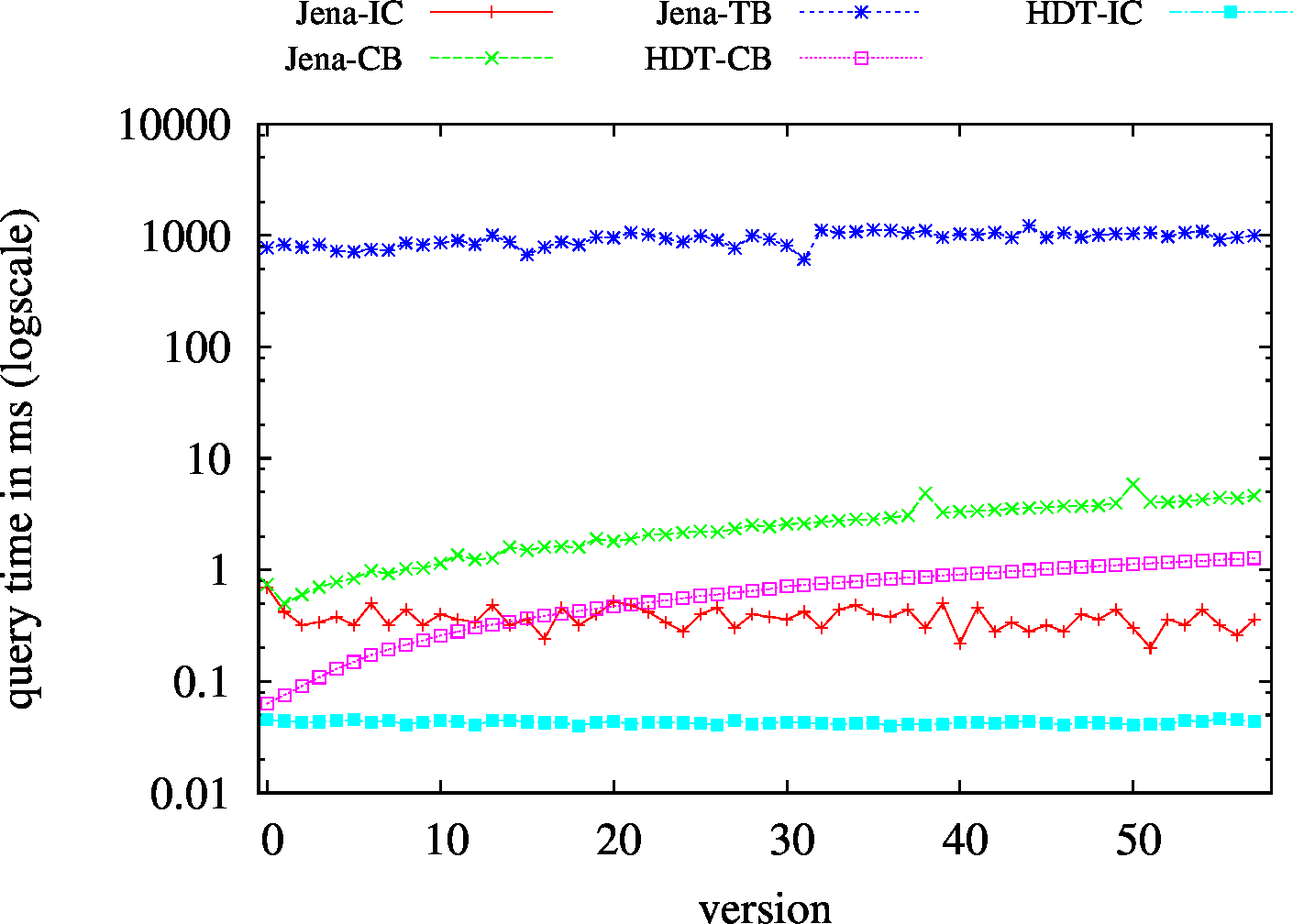
|
|
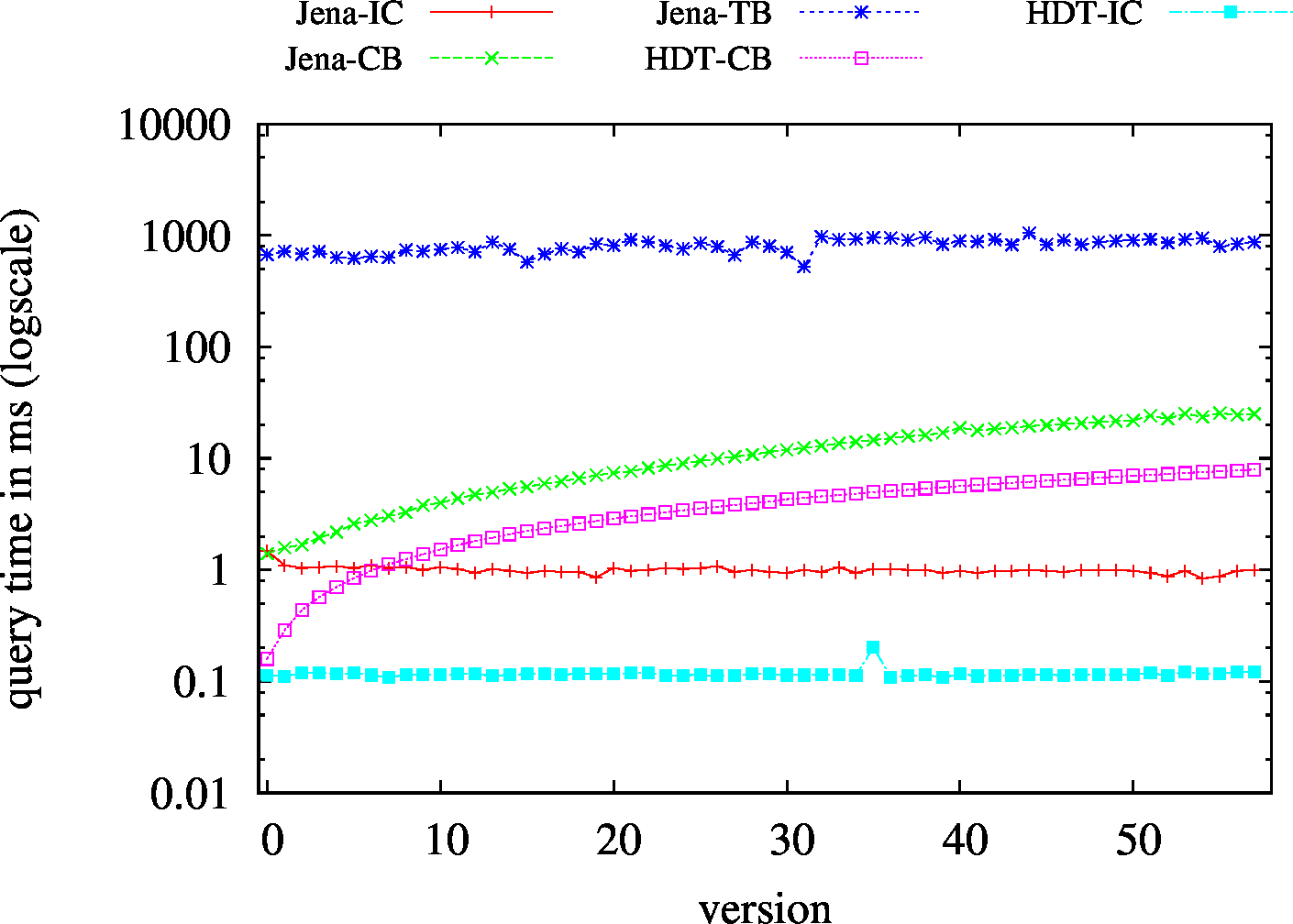
| ?P? - Low Cardinality | ?P? - High Cardinality |
|
|
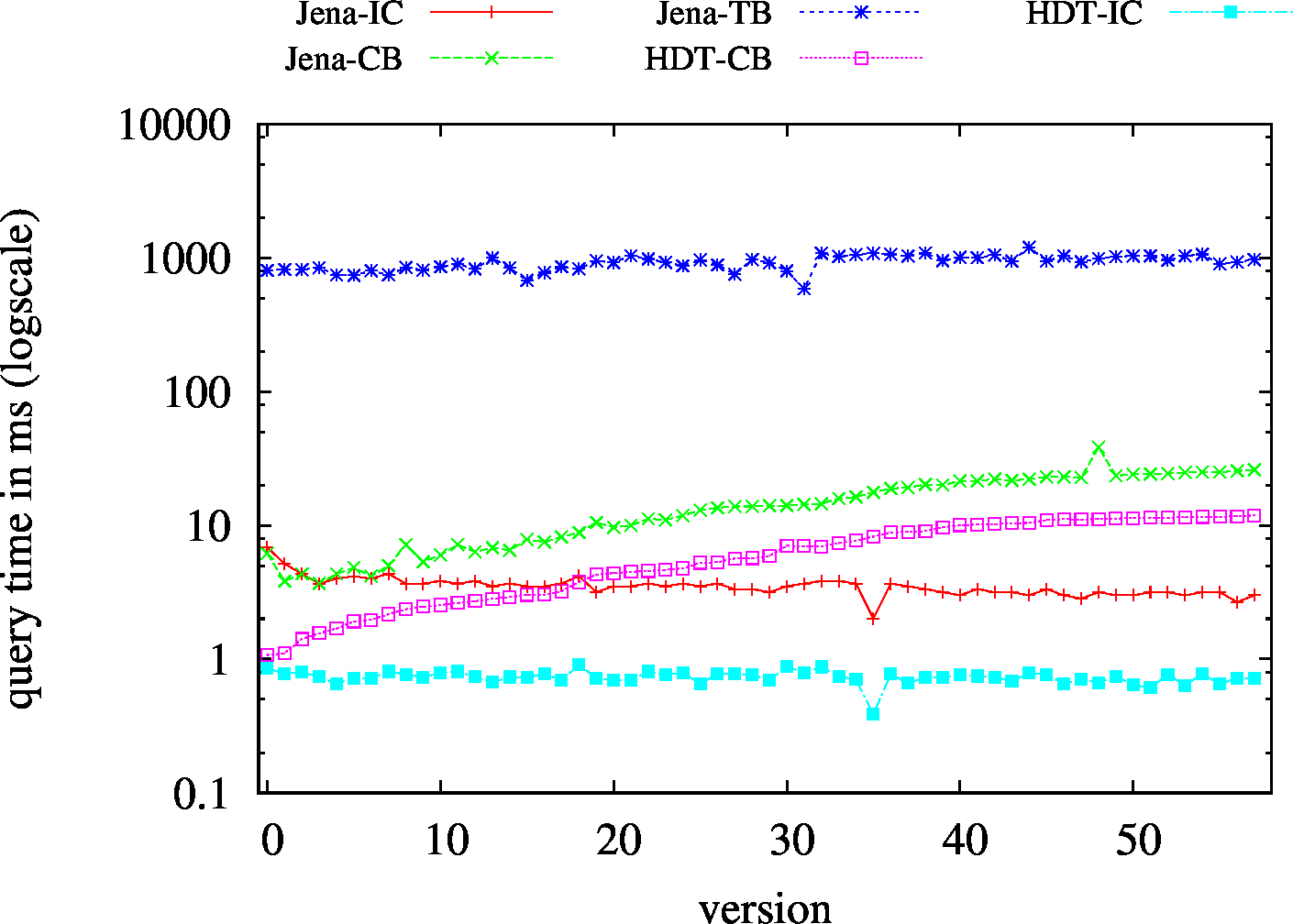
| ??O - Low Cardinality | ??O - High Cardinality |
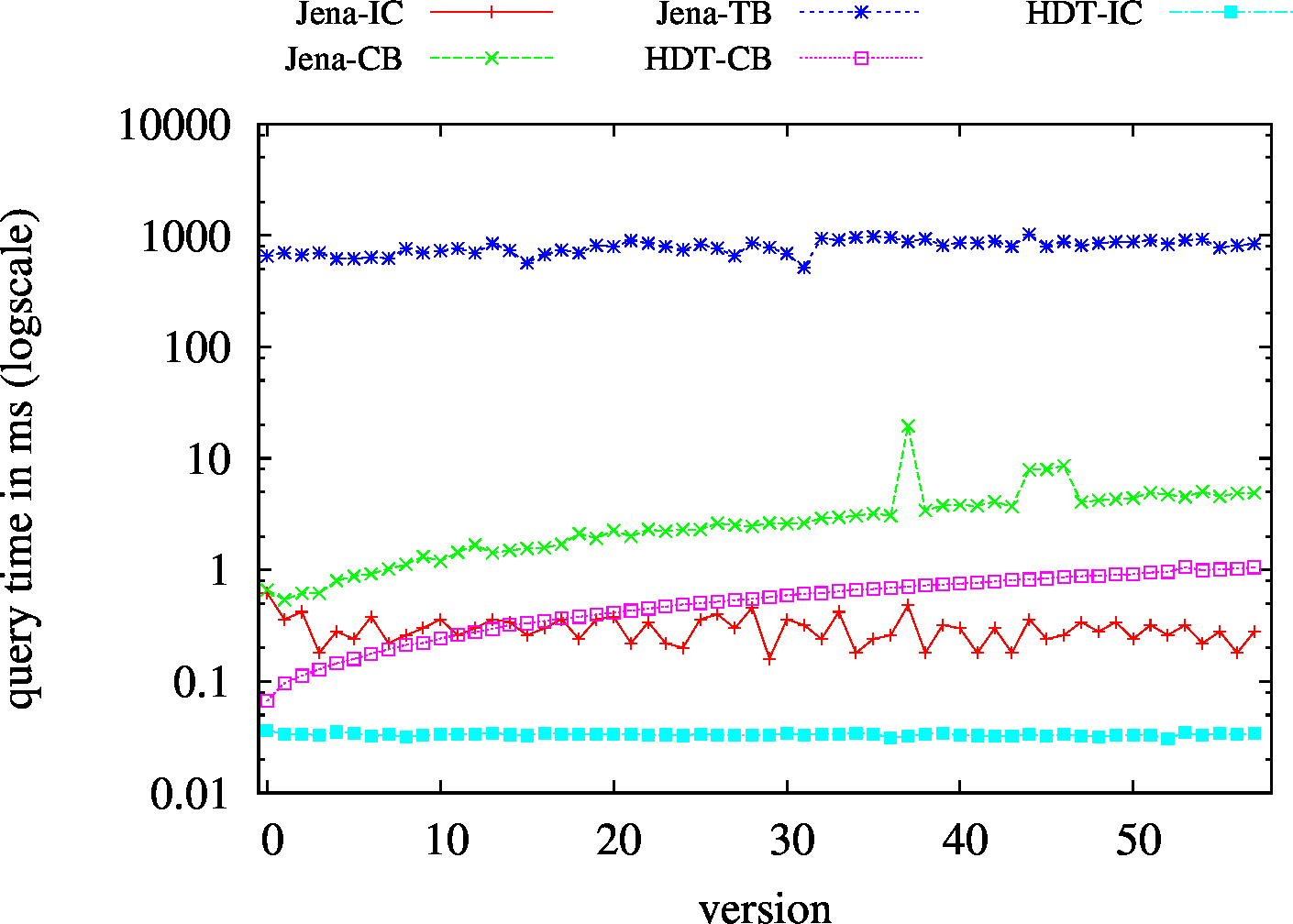
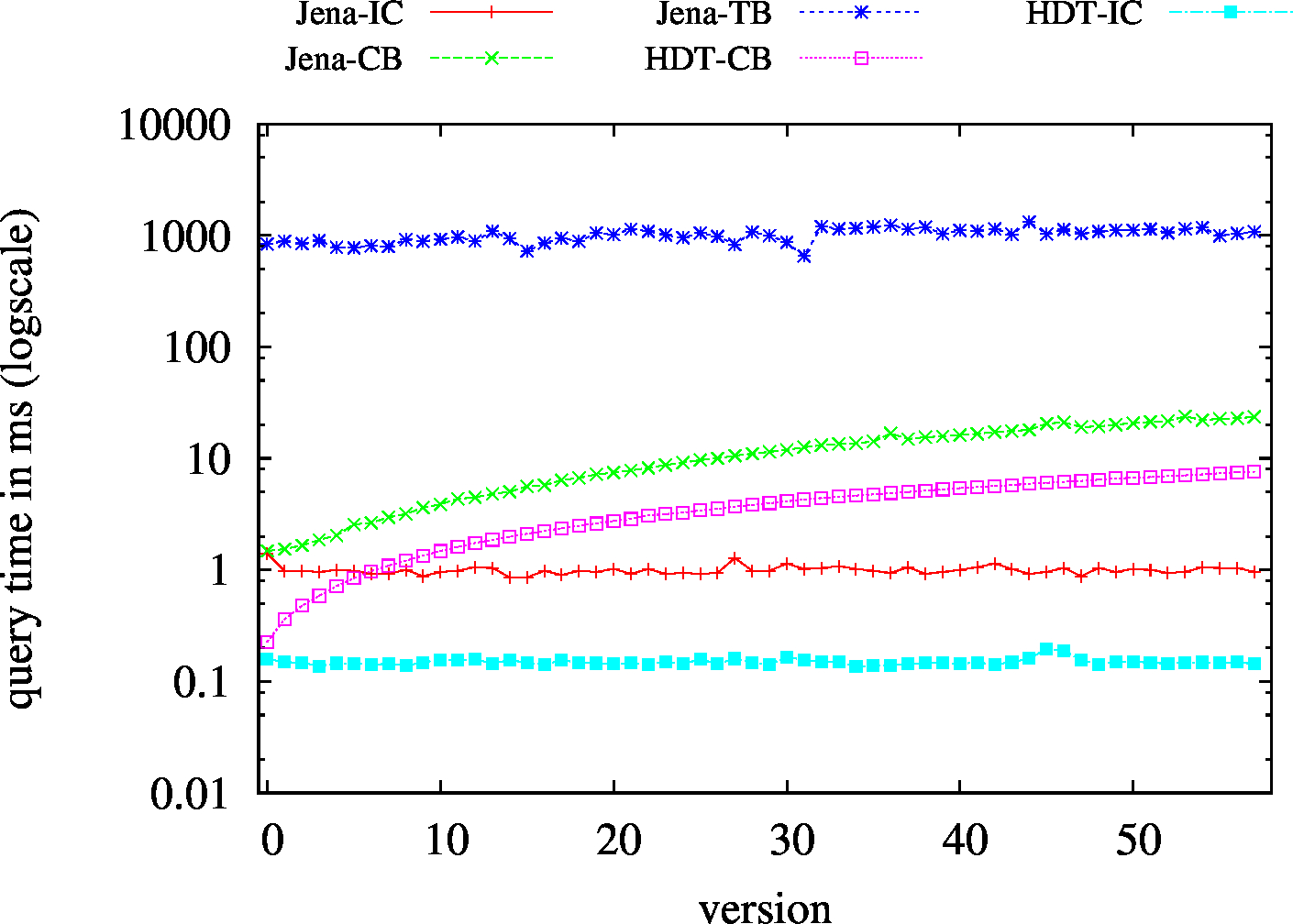
|
|
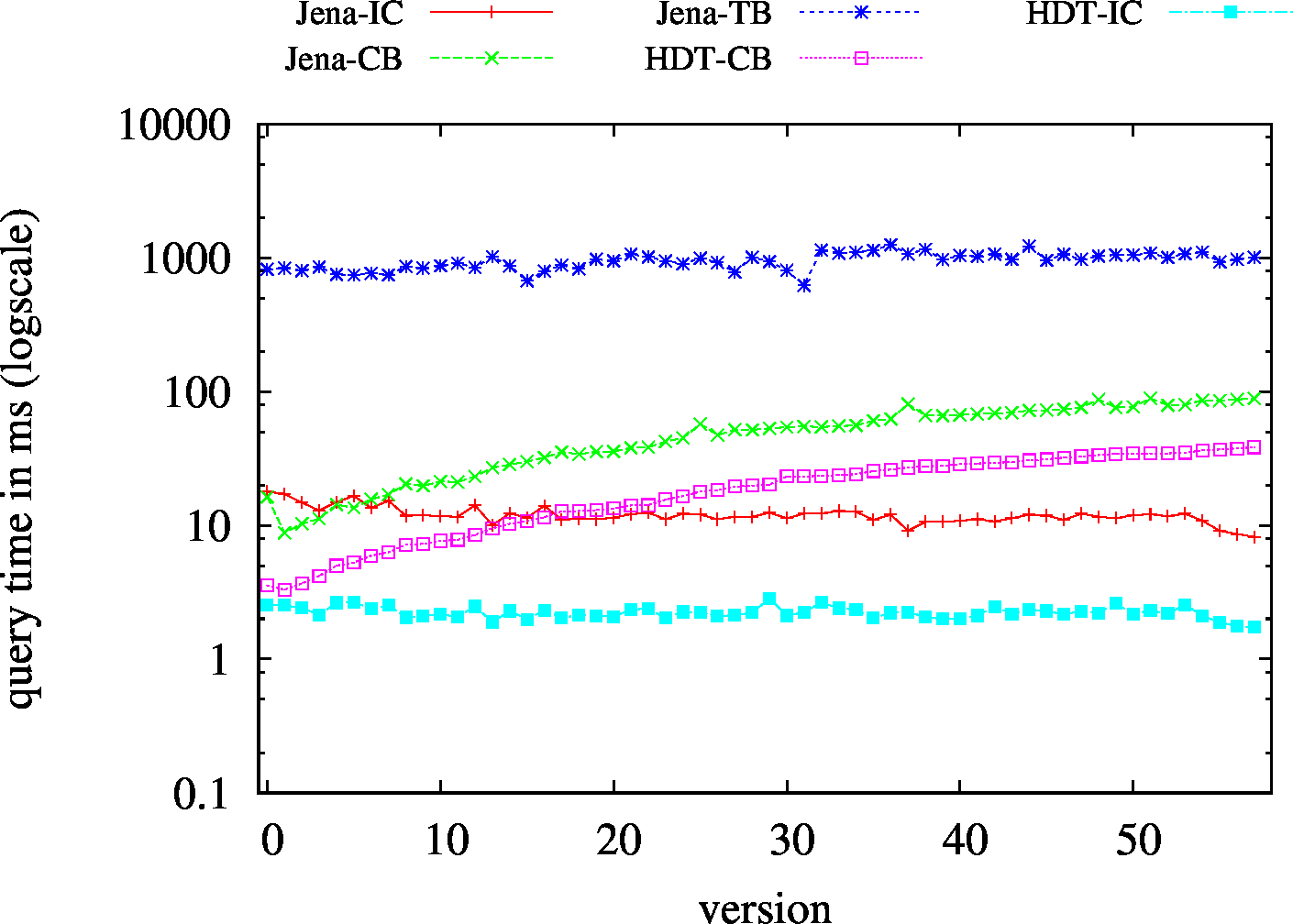
| SP? - Low Cardinality | SP? - High Cardinality |
|---|---|
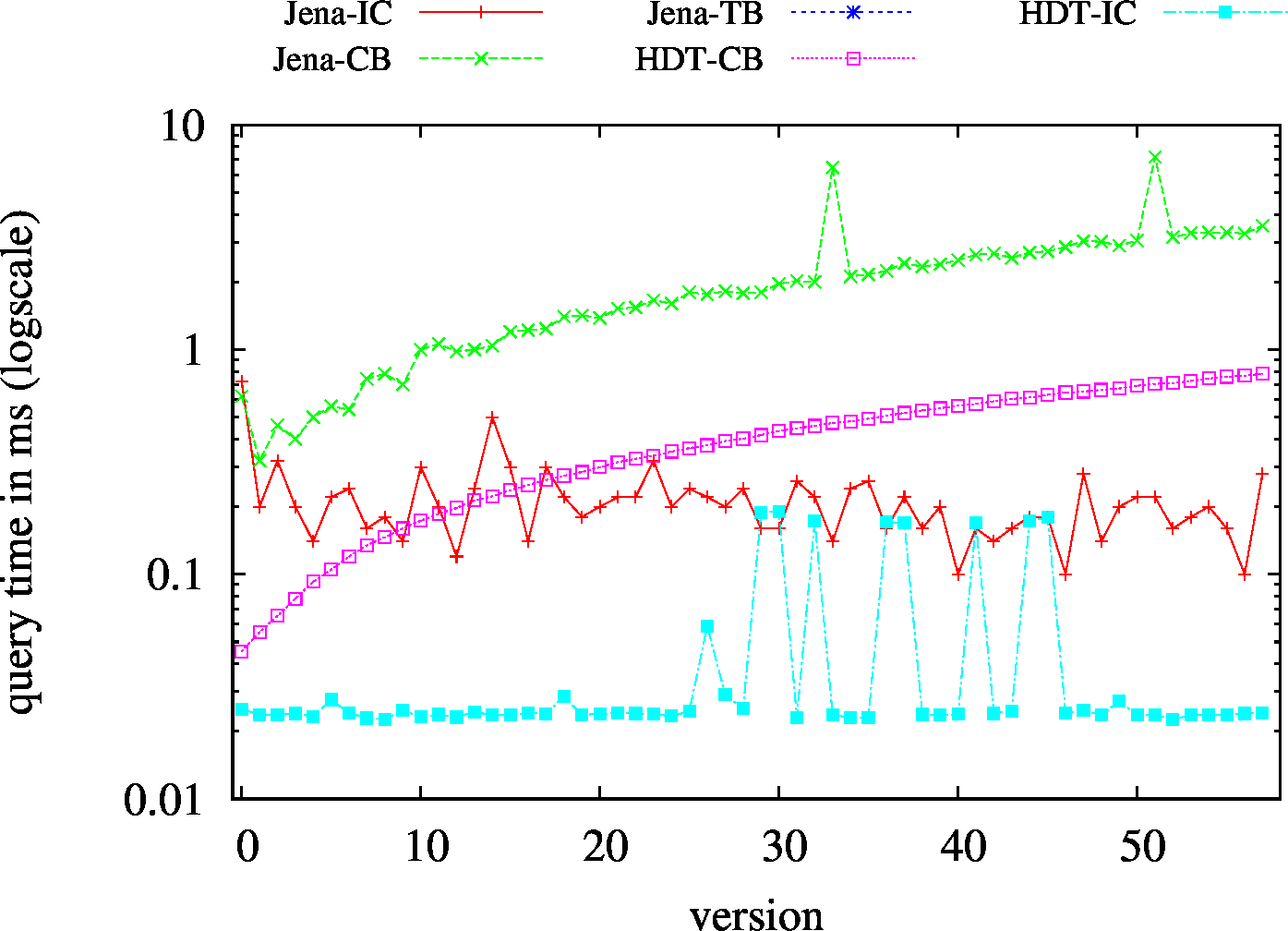
|
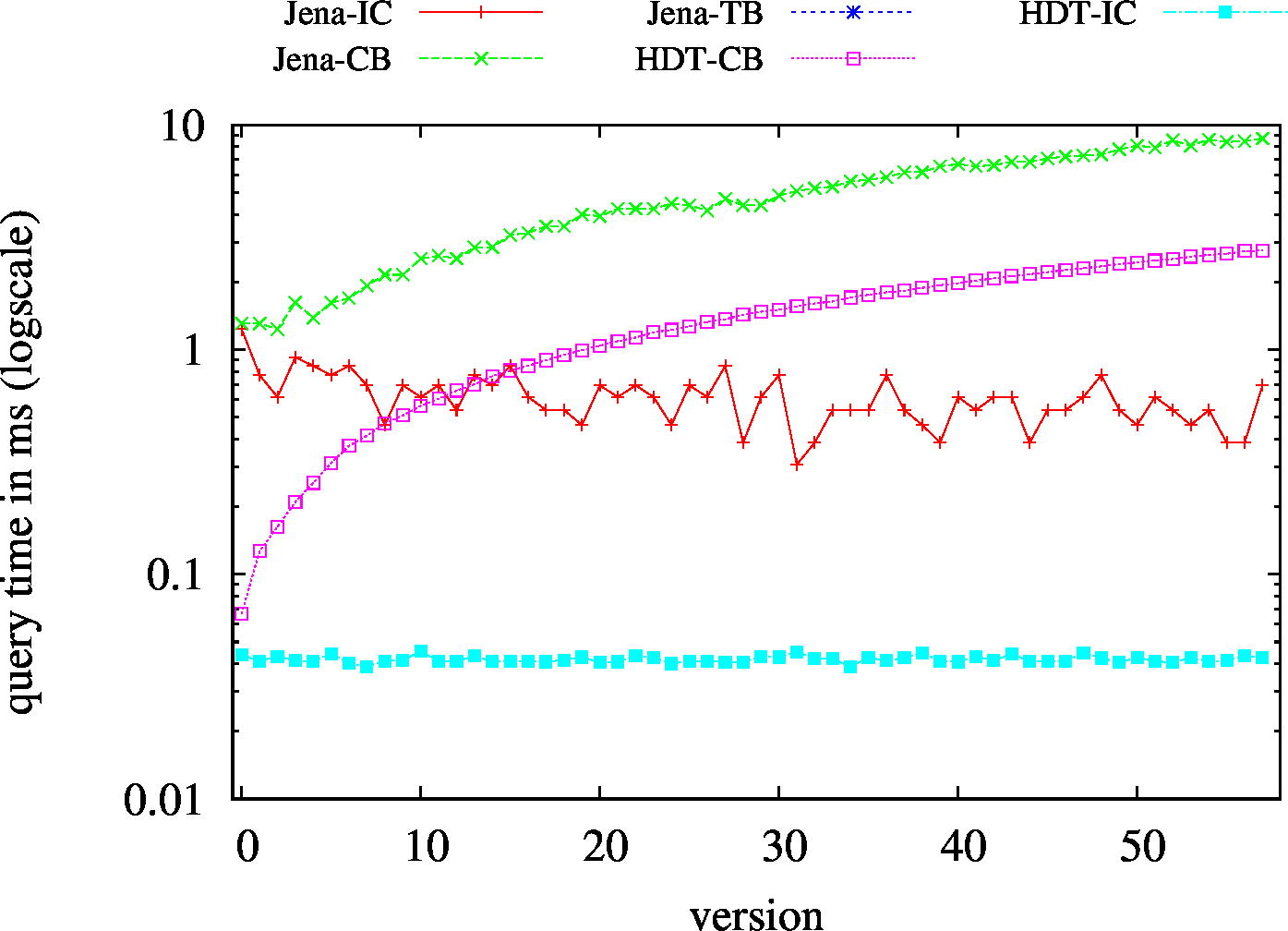
|
| ?PO - Low Cardinality | ?PO - High Cardinality |

|
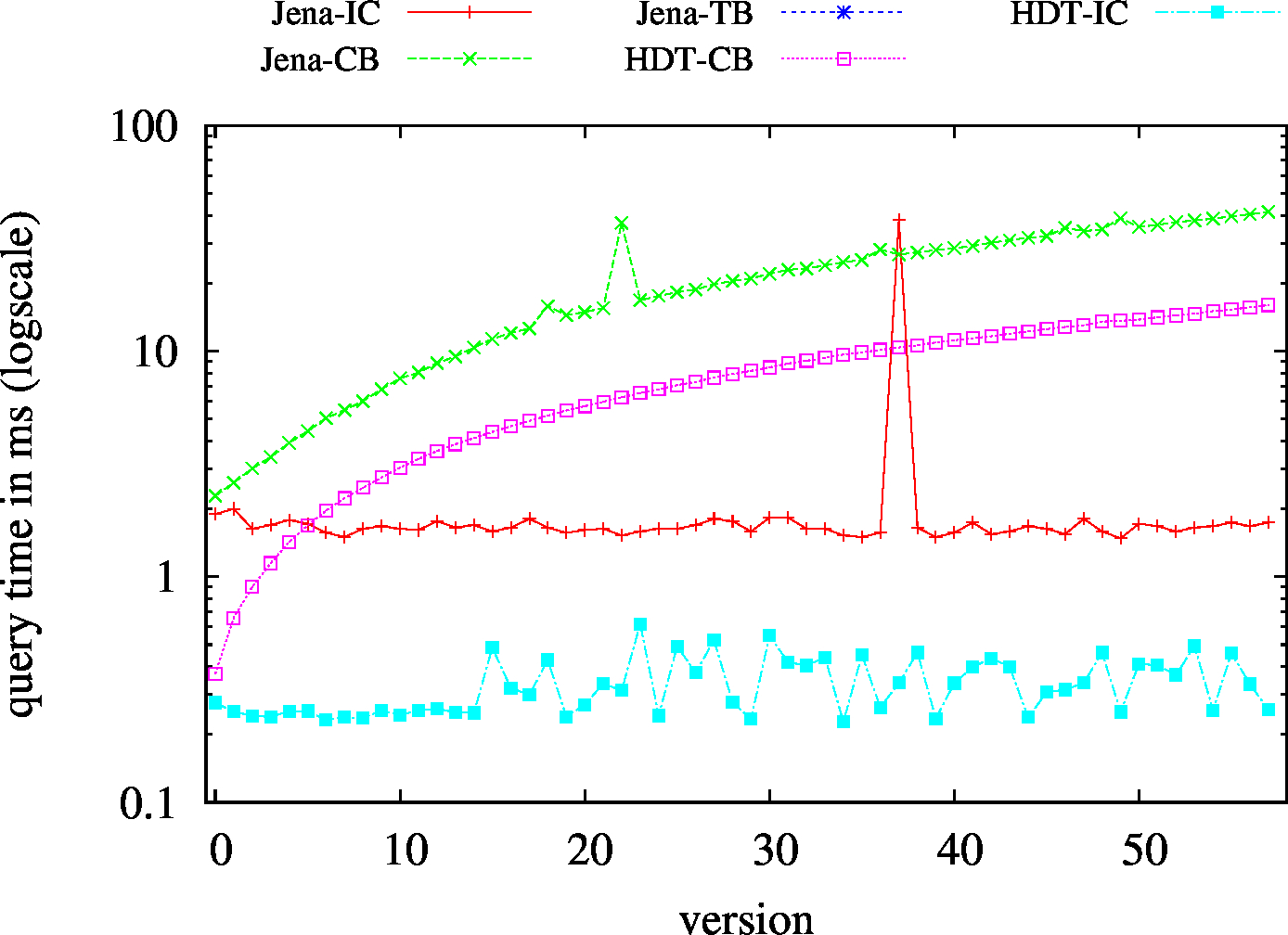
|
| S?O - Low Cardinality | SPO |
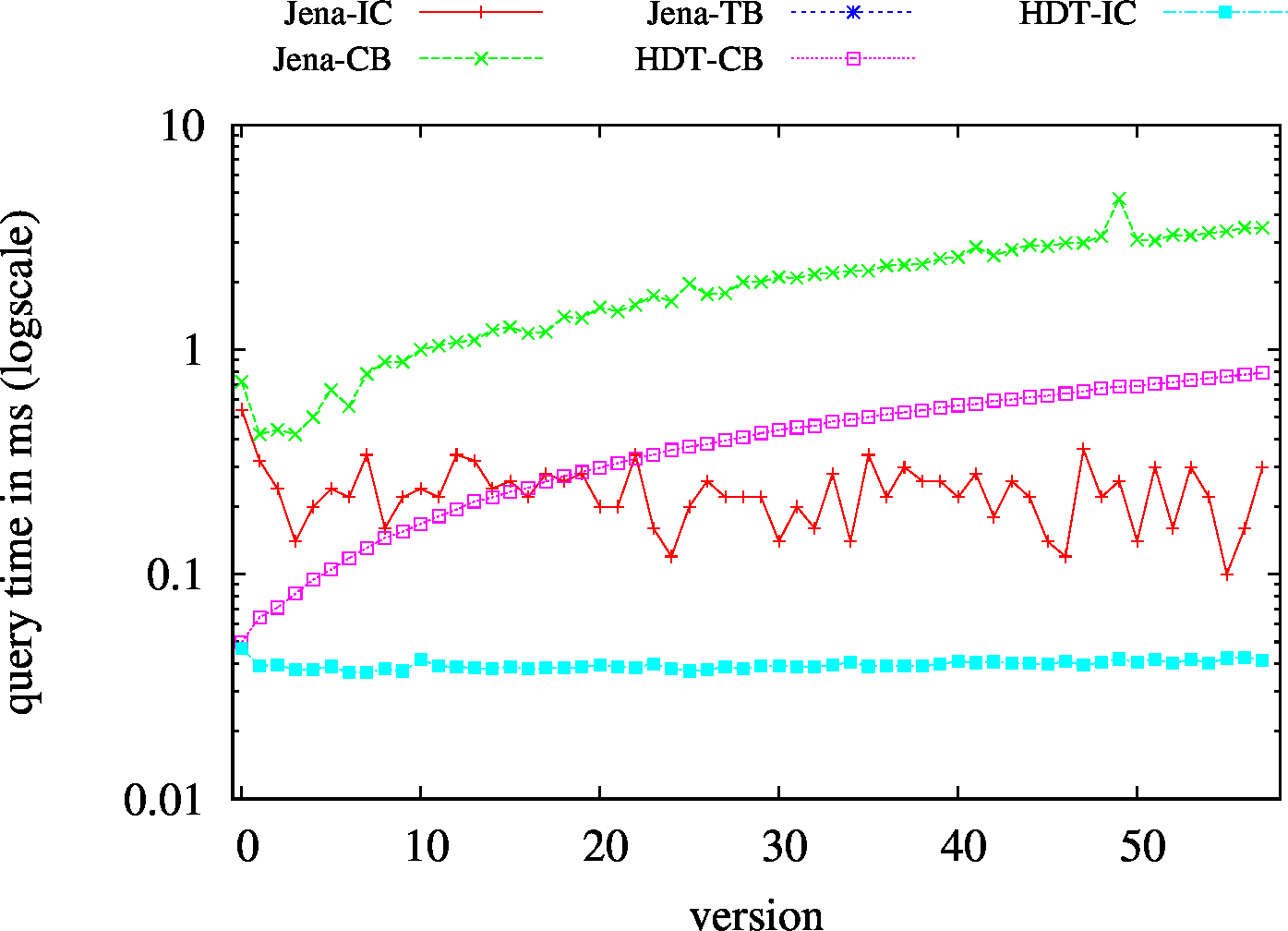
|
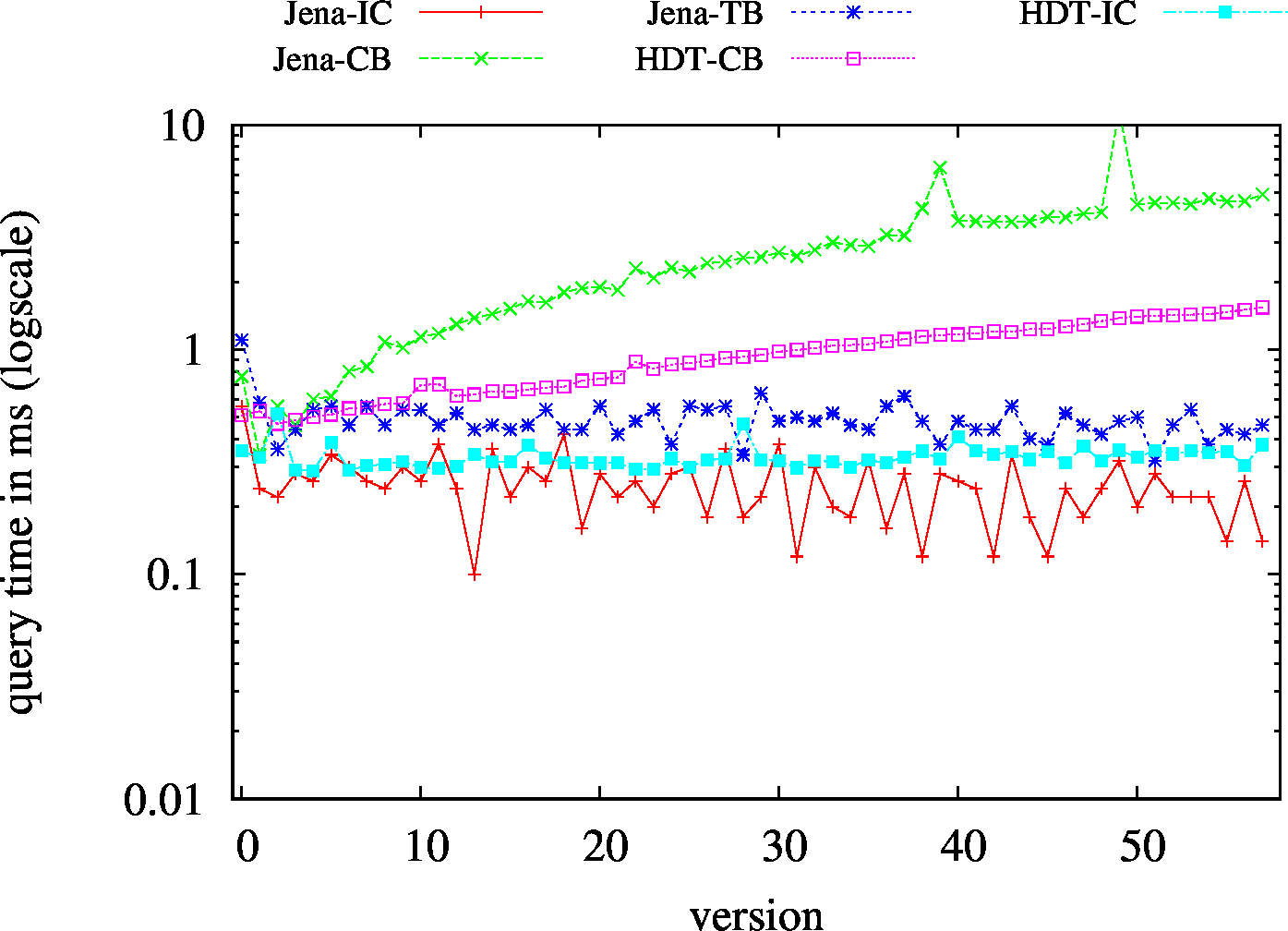
|
| S?? - Low Cardinality | S?? - High Cardinality |
|---|---|
|
|
| ?P? - Low Cardinality | ?P? - High Cardinality |
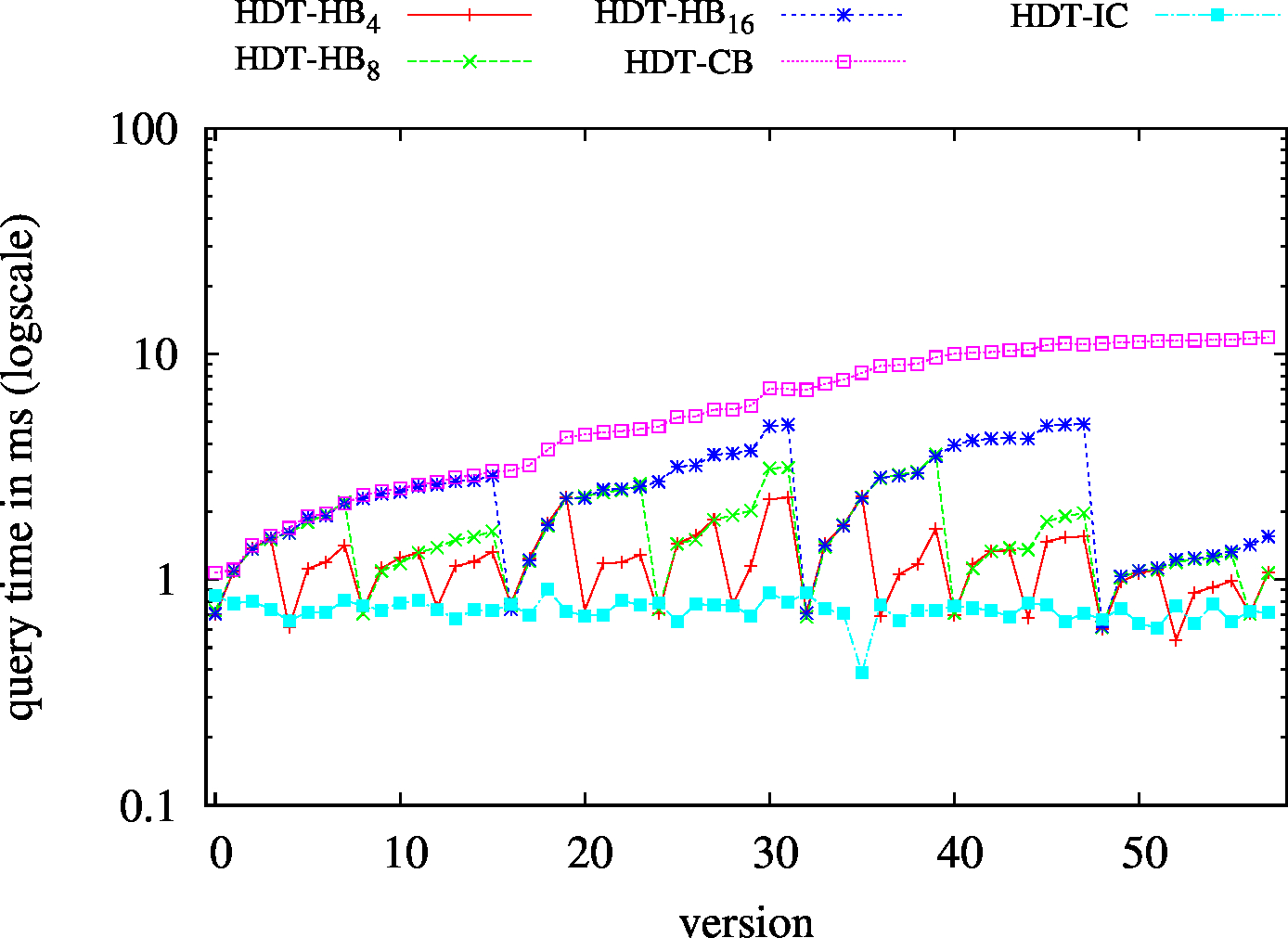
|
|
| ??O - Low Cardinality | ??O - High Cardinality |
|
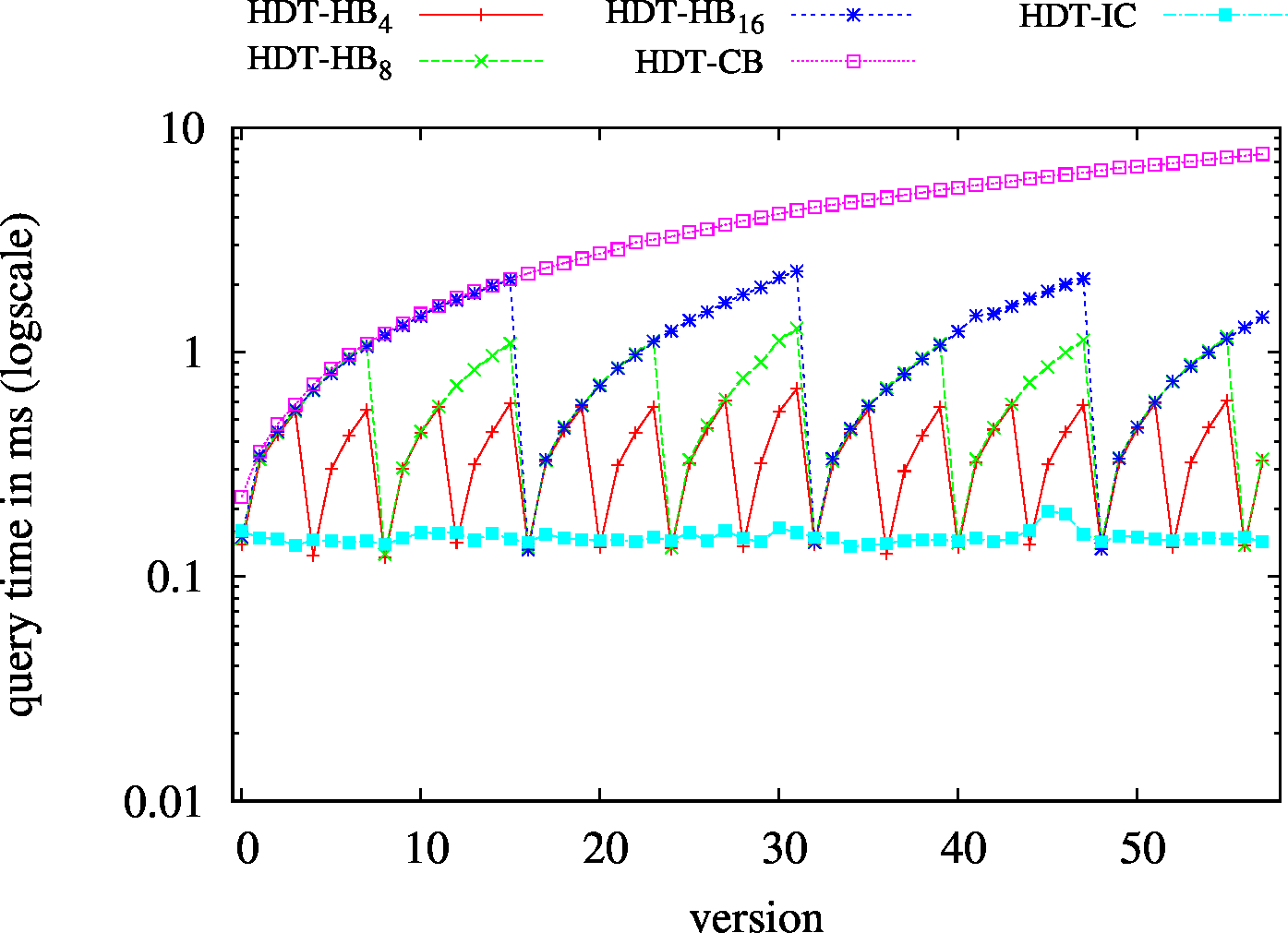
|
| SP? - Low Cardinality | SP? - High Cardinality |
|---|---|
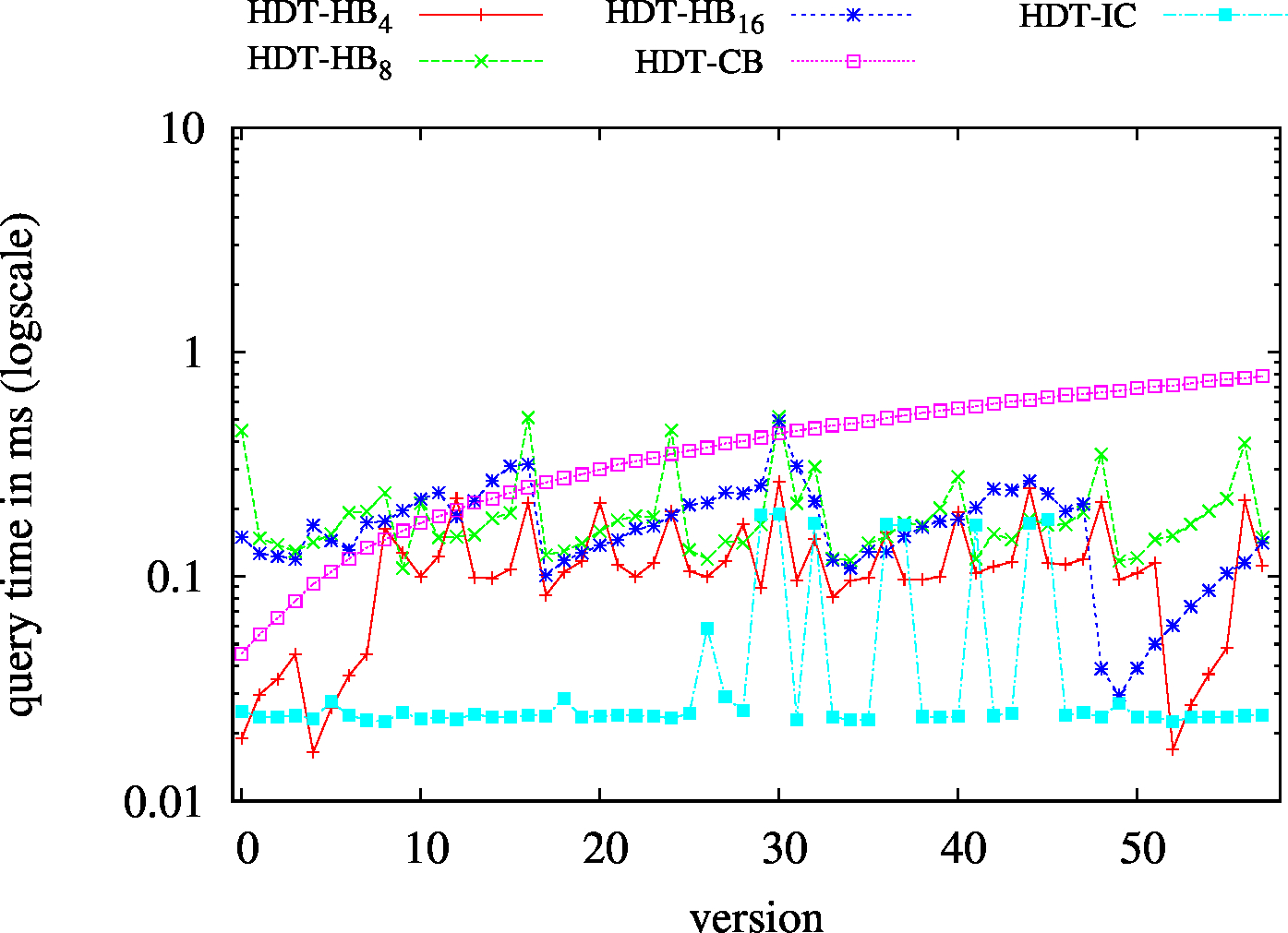
|
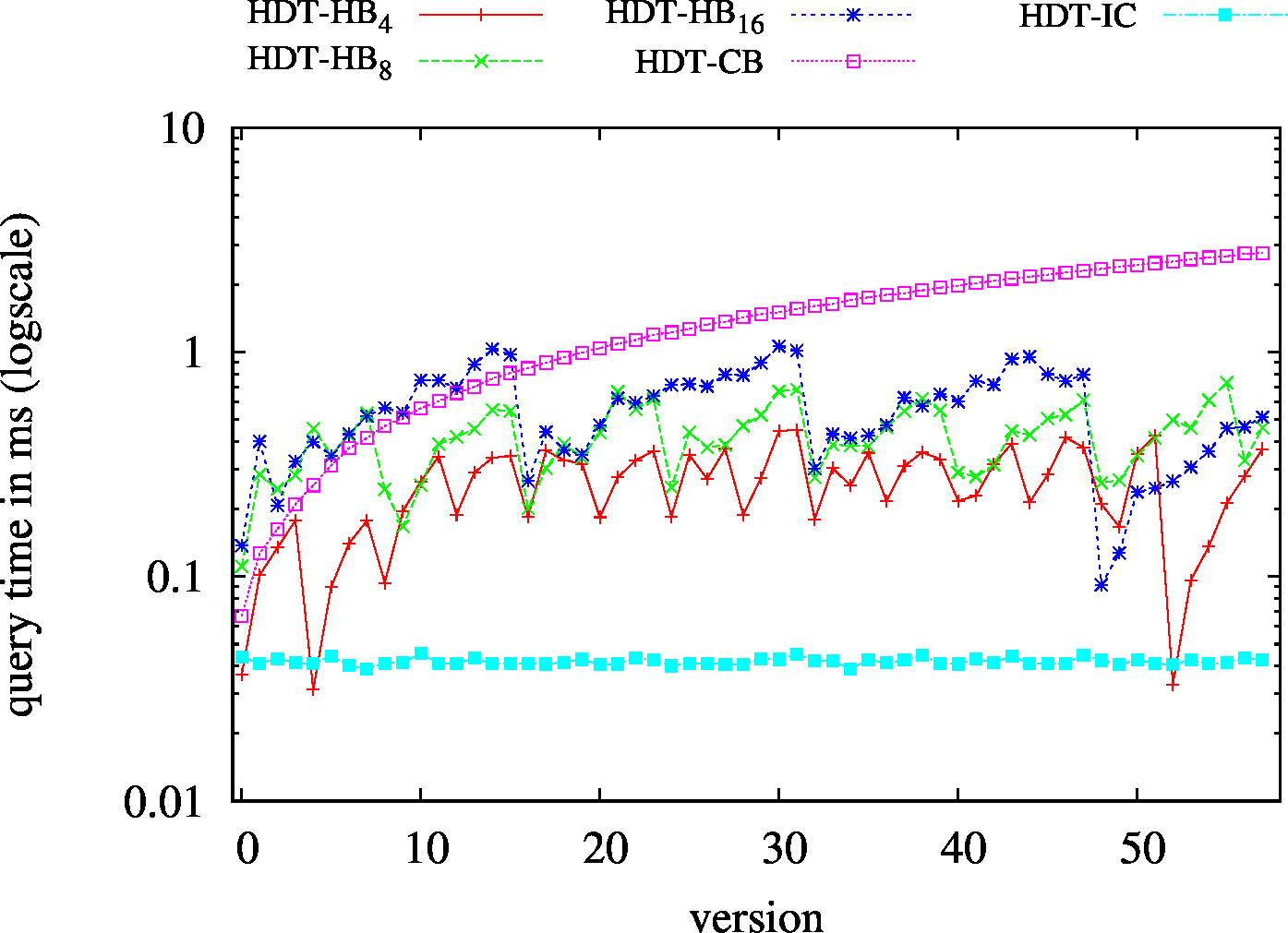
|
| ?PO - Low Cardinality | ?PO - High Cardinality |
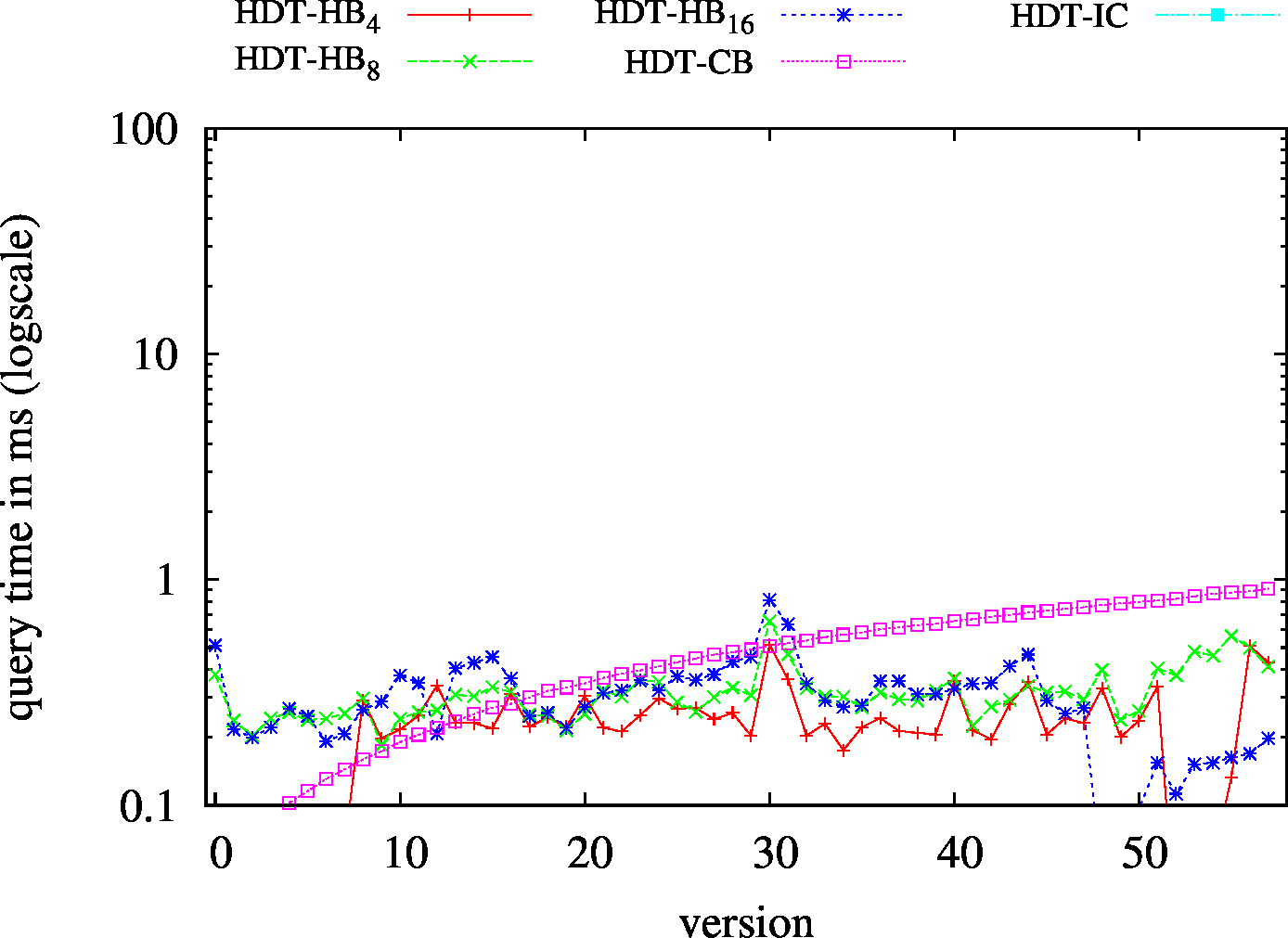
|
|
| S?O - Low Cardinality | SPO |
|
|
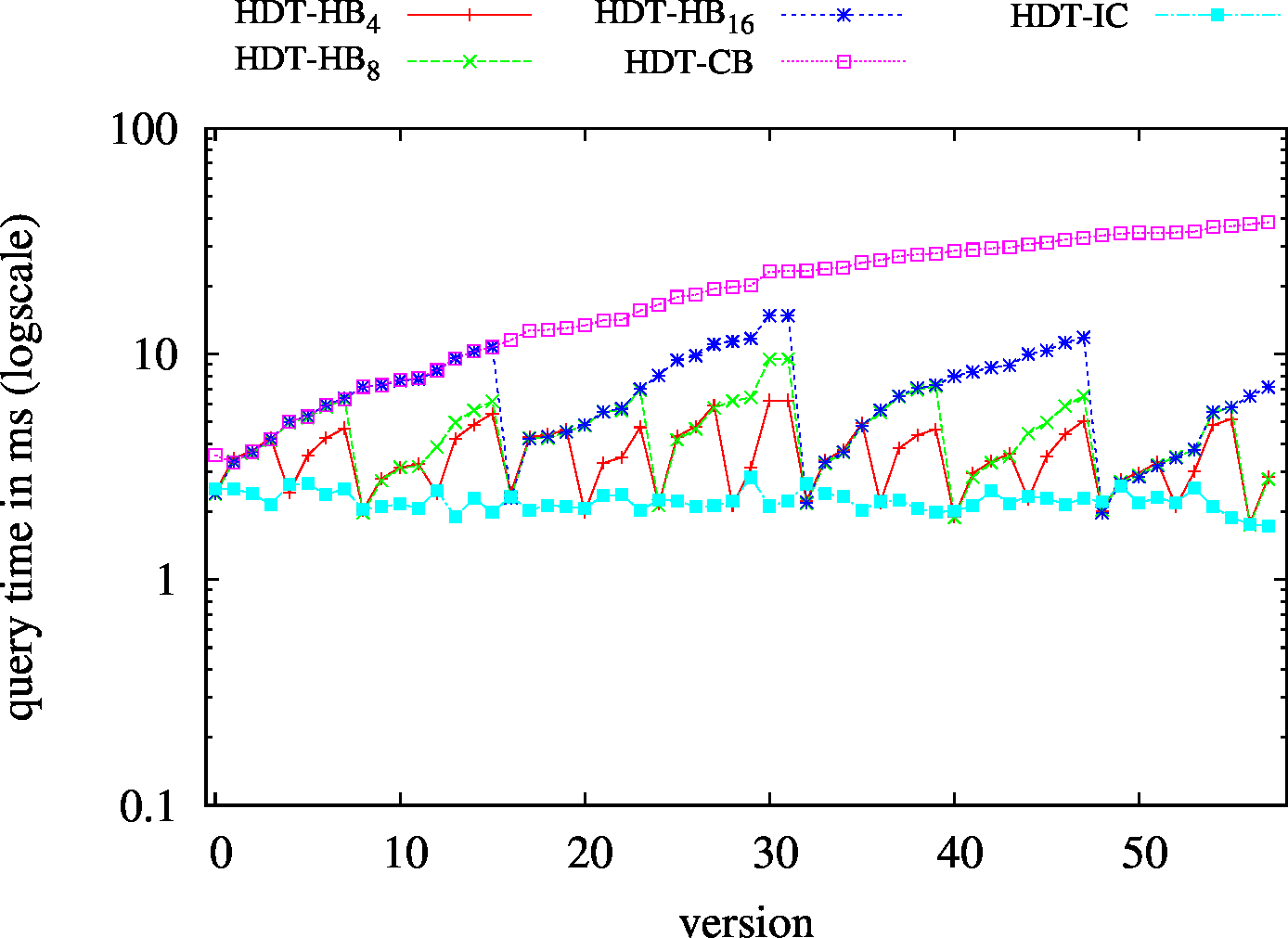
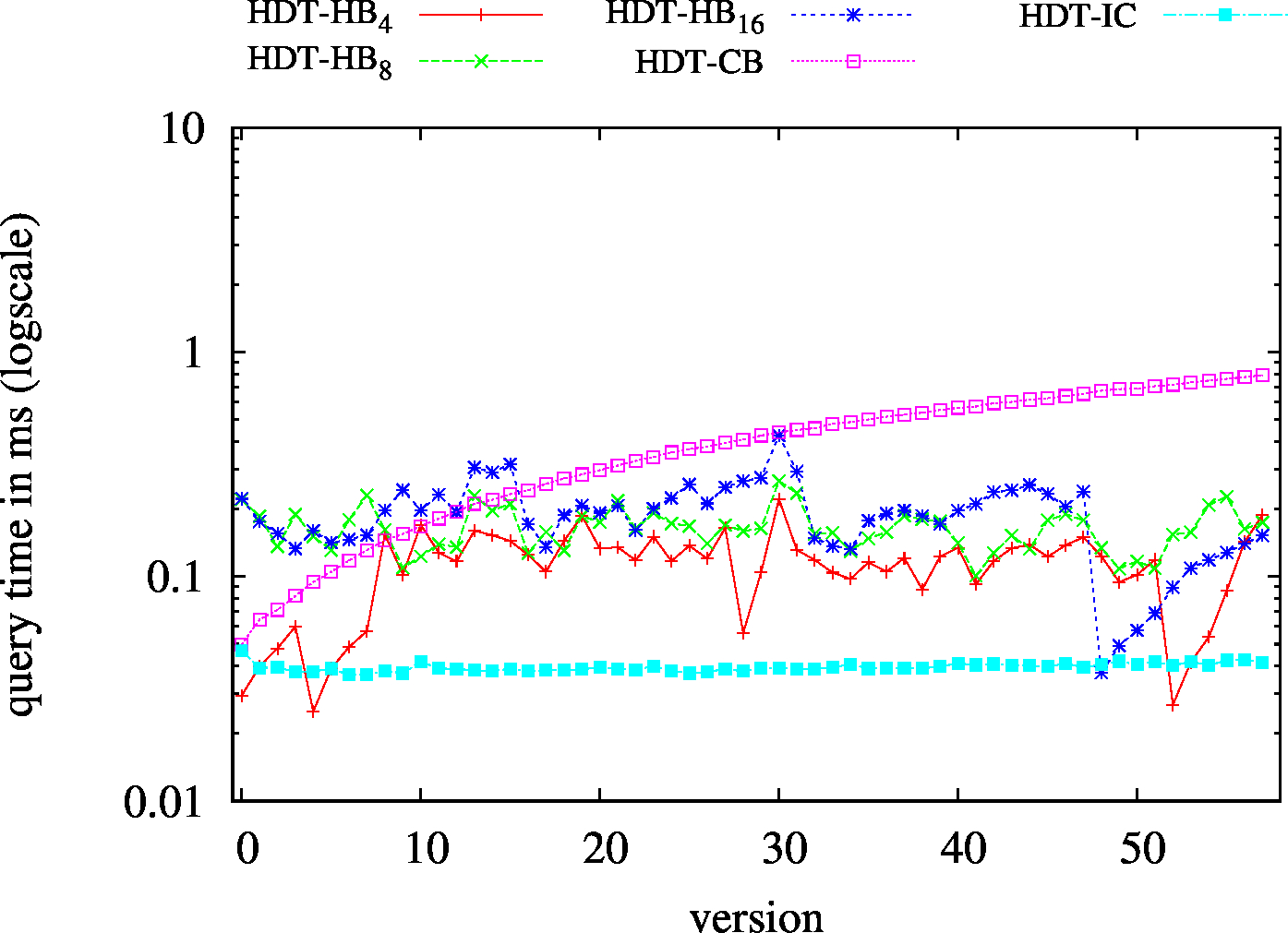
| S?? - Low Cardinality | S?? - High Cardinality |
|---|---|
|
|
| ?P? - Low Cardinality | ?P? - High Cardinality |
|
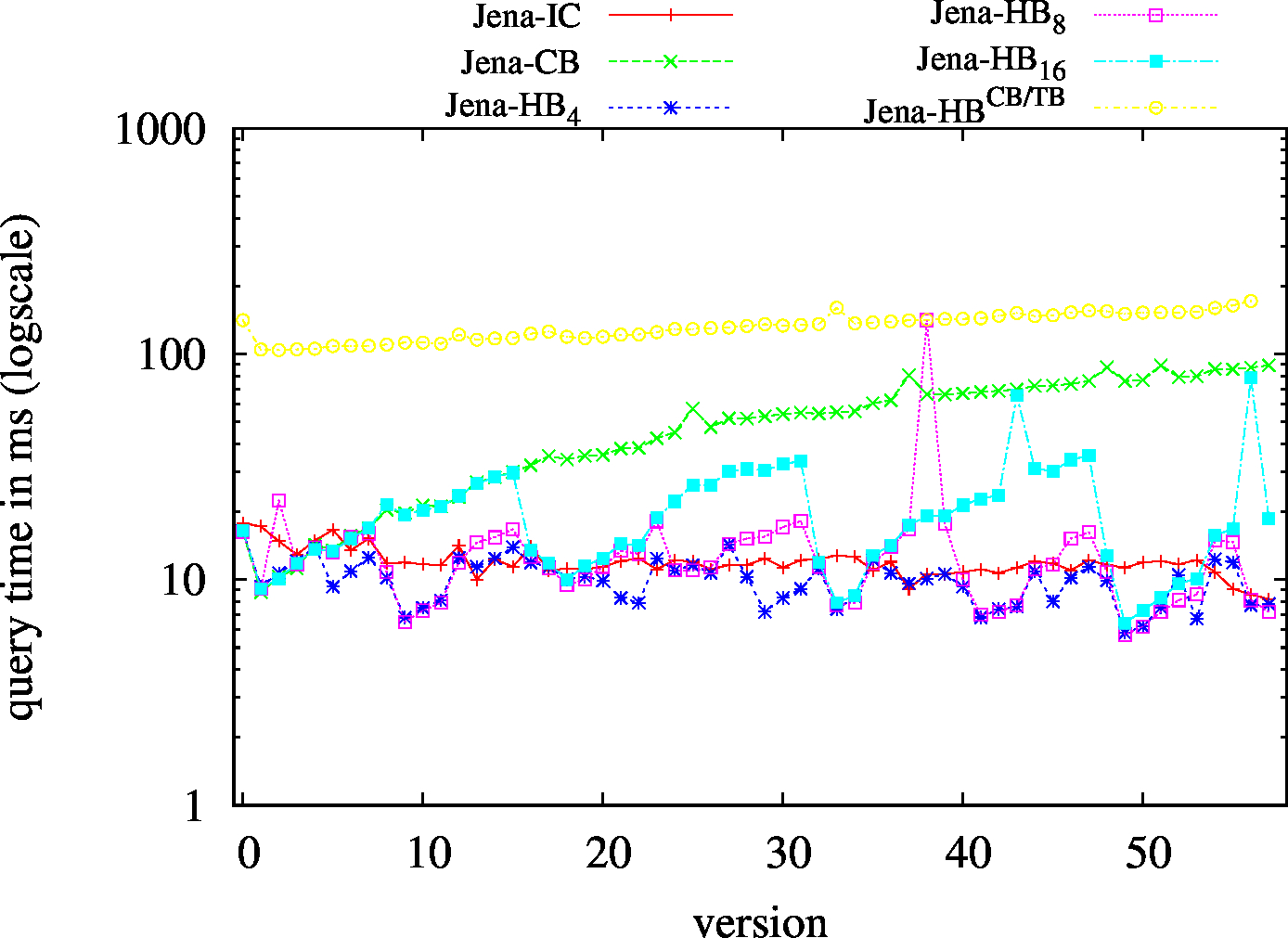
|
| ??O - Low Cardinality | ??O - High Cardinality |
|
|
| SP? - Low Cardinality | SP? - High Cardinality |
|---|---|
|
|
| ?PO - Low Cardinality | ?PO - High Cardinality |
|
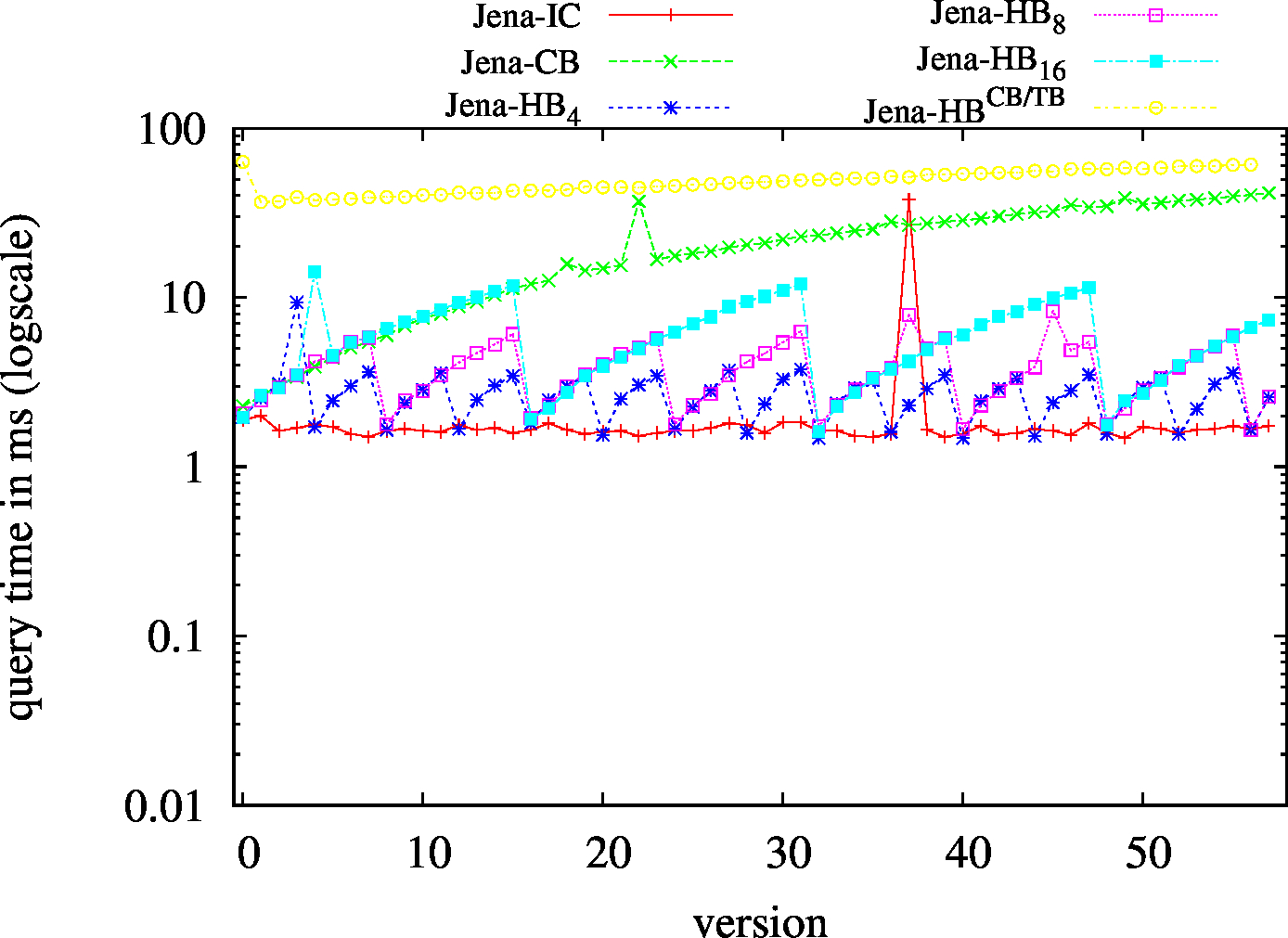
|
| S?O - Low Cardinality | SPO |
|
|
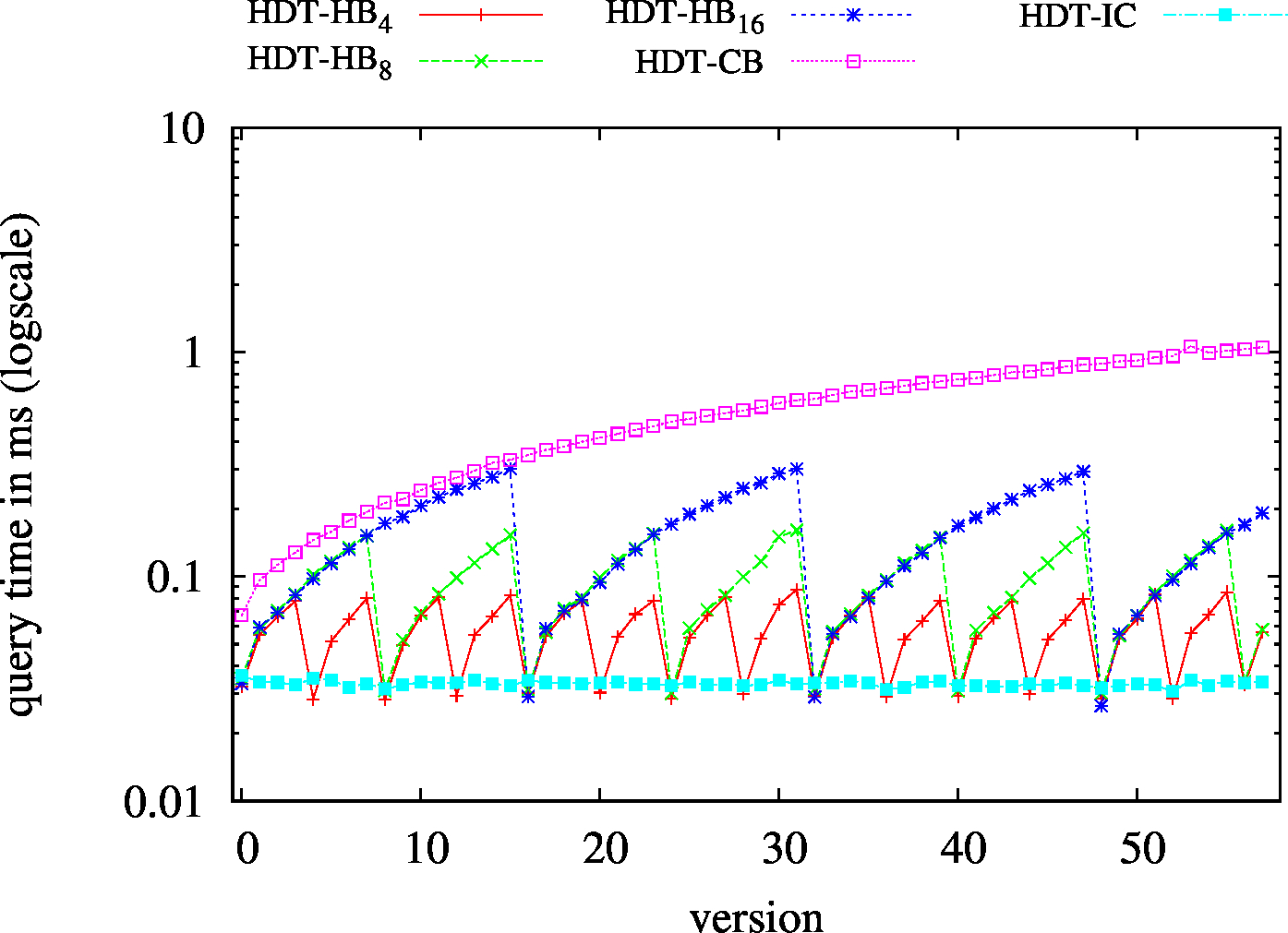
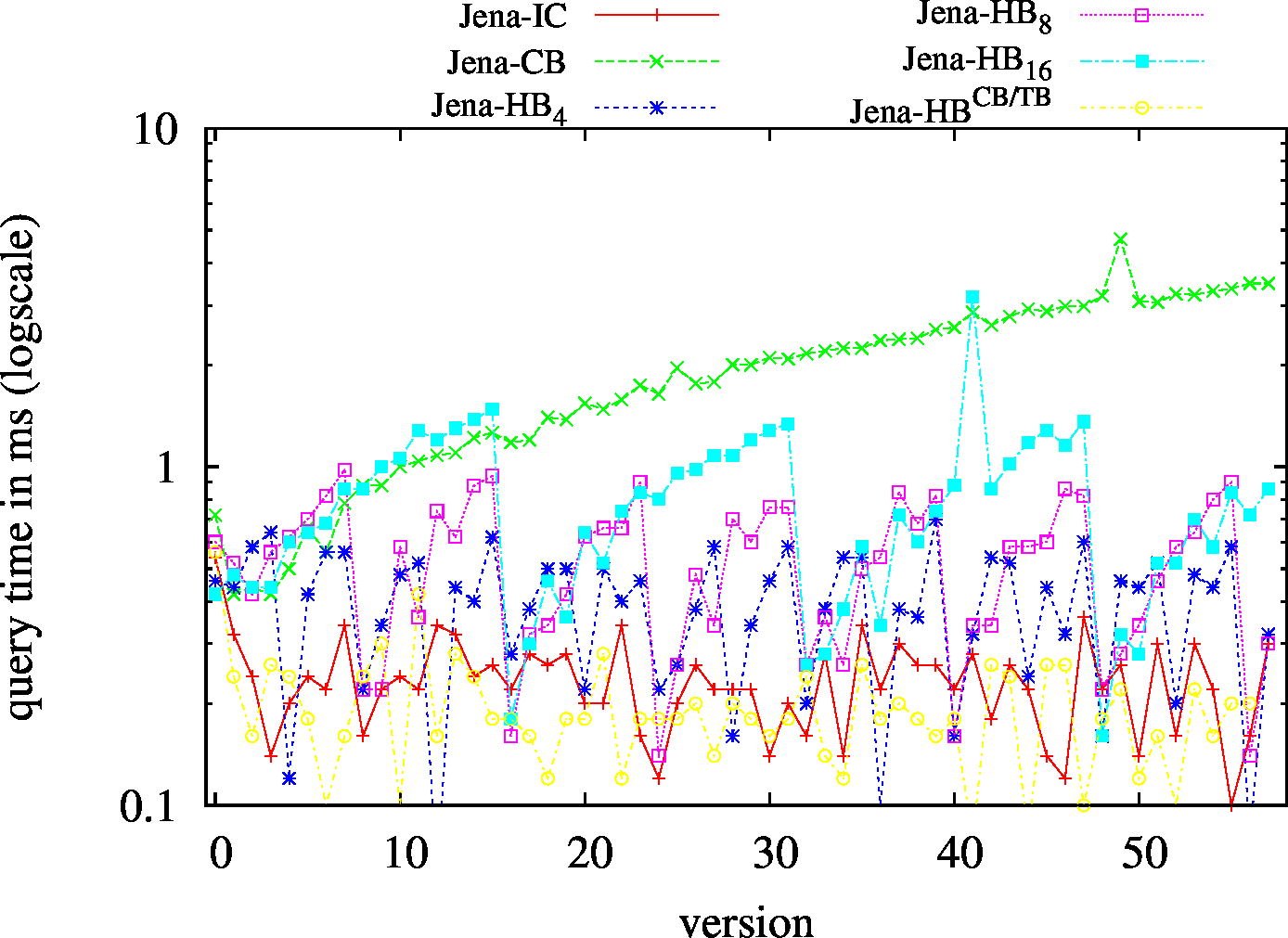
| S?? - Low Cardinality | S?? - High Cardinality |
|---|---|
|
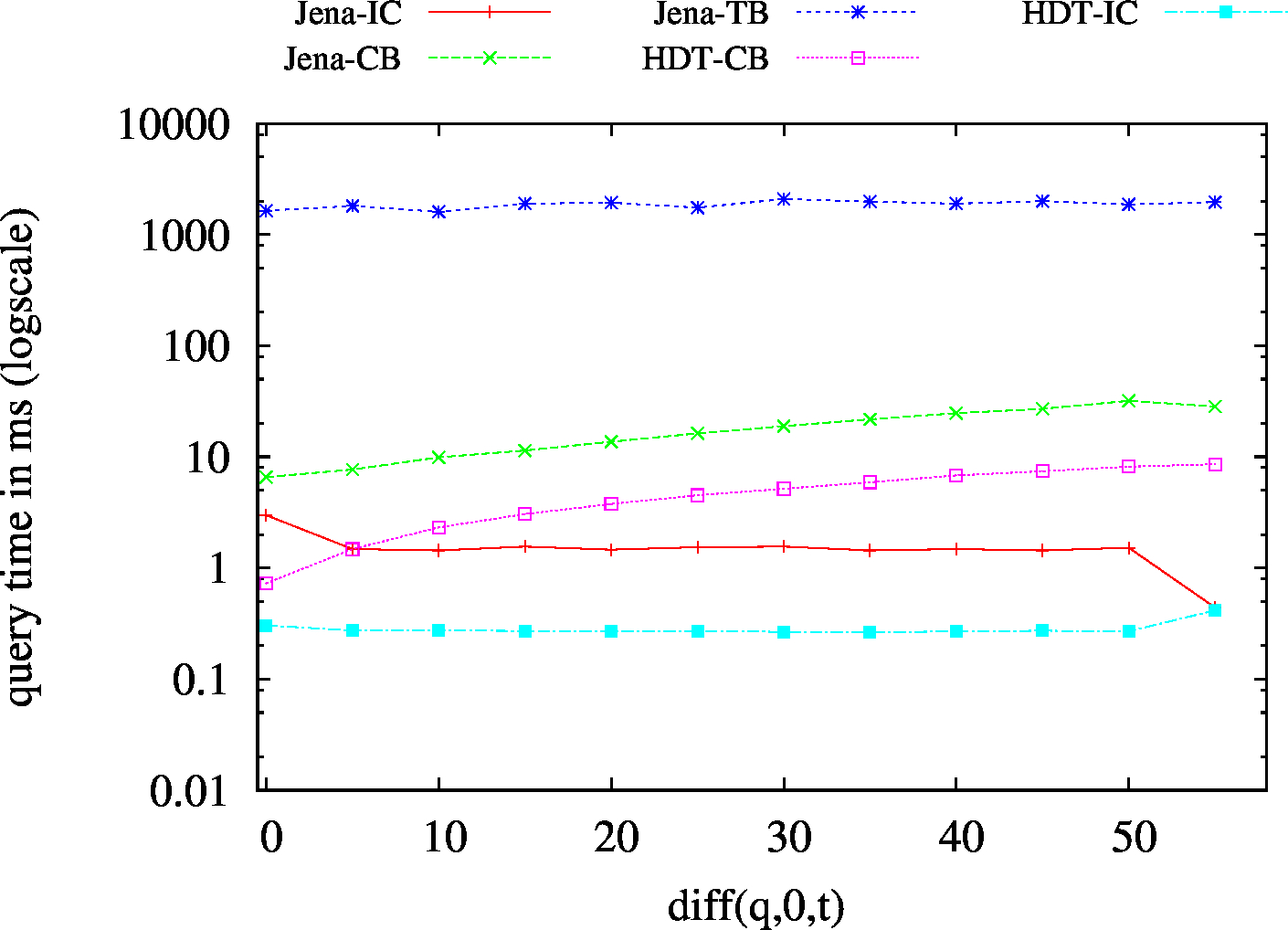
|
| ?P? - Low Cardinality | ?P? - High Cardinality |
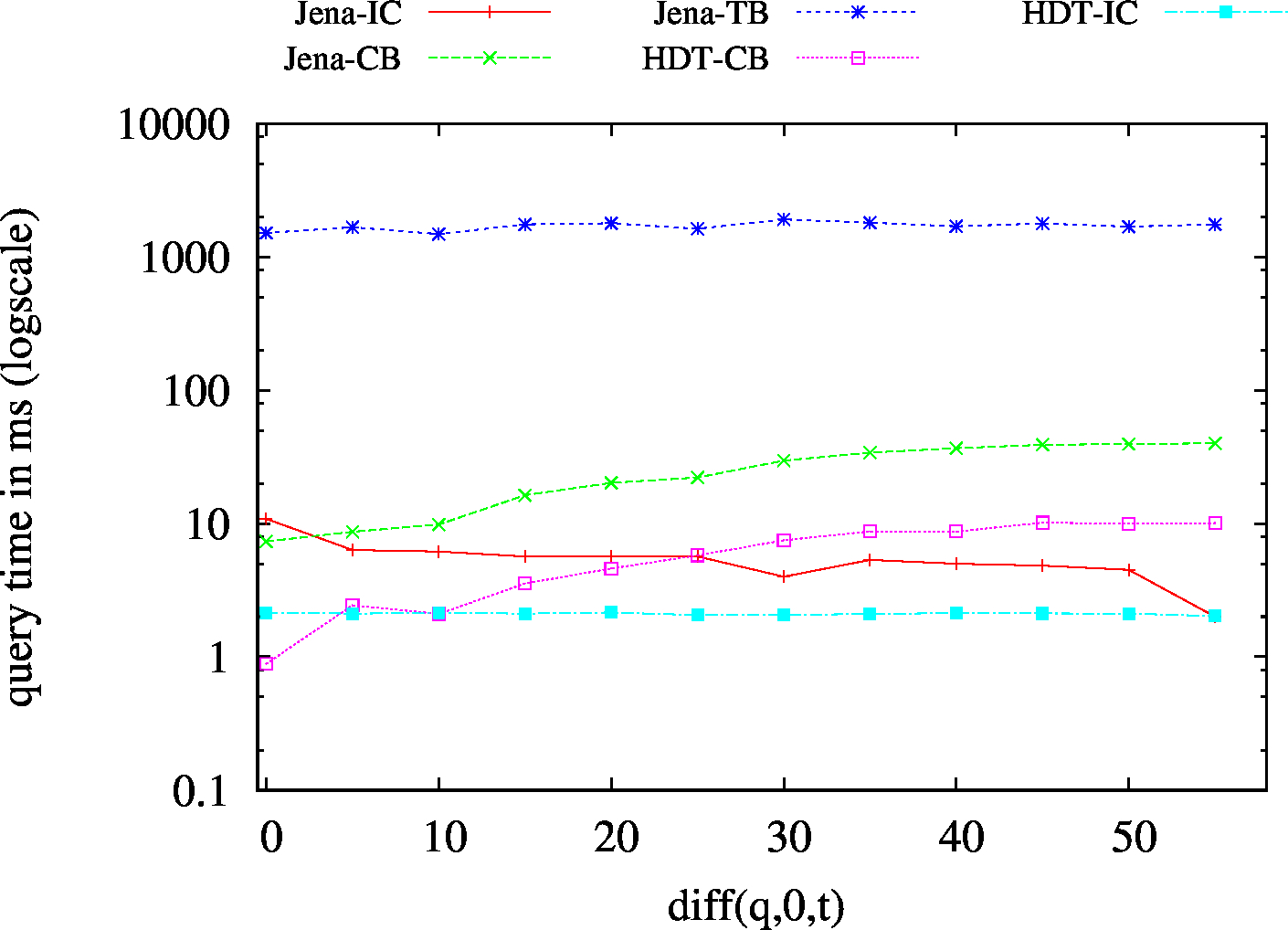
|

|
| ??O - Low Cardinality | ??O - High Cardinality |
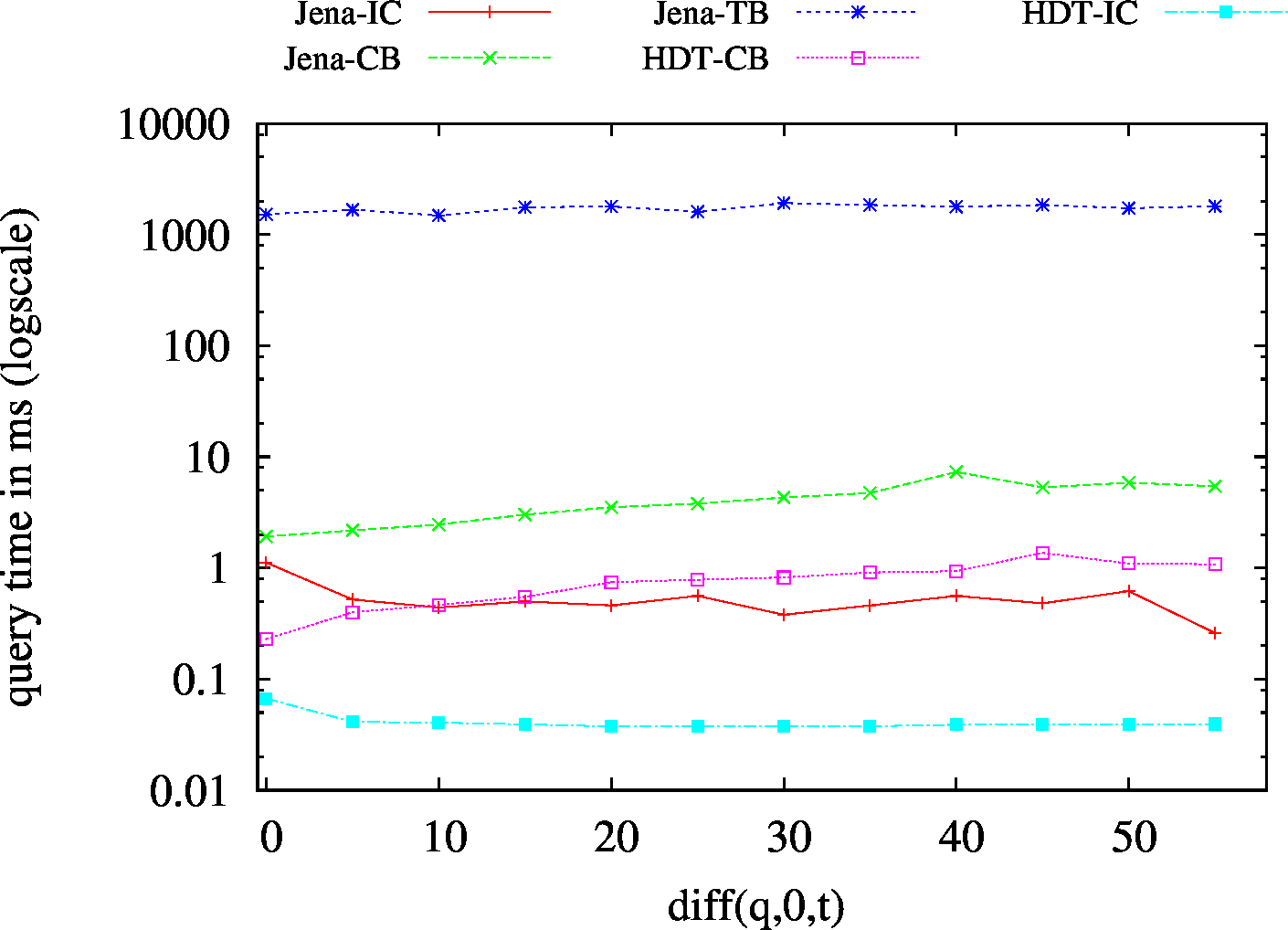
|
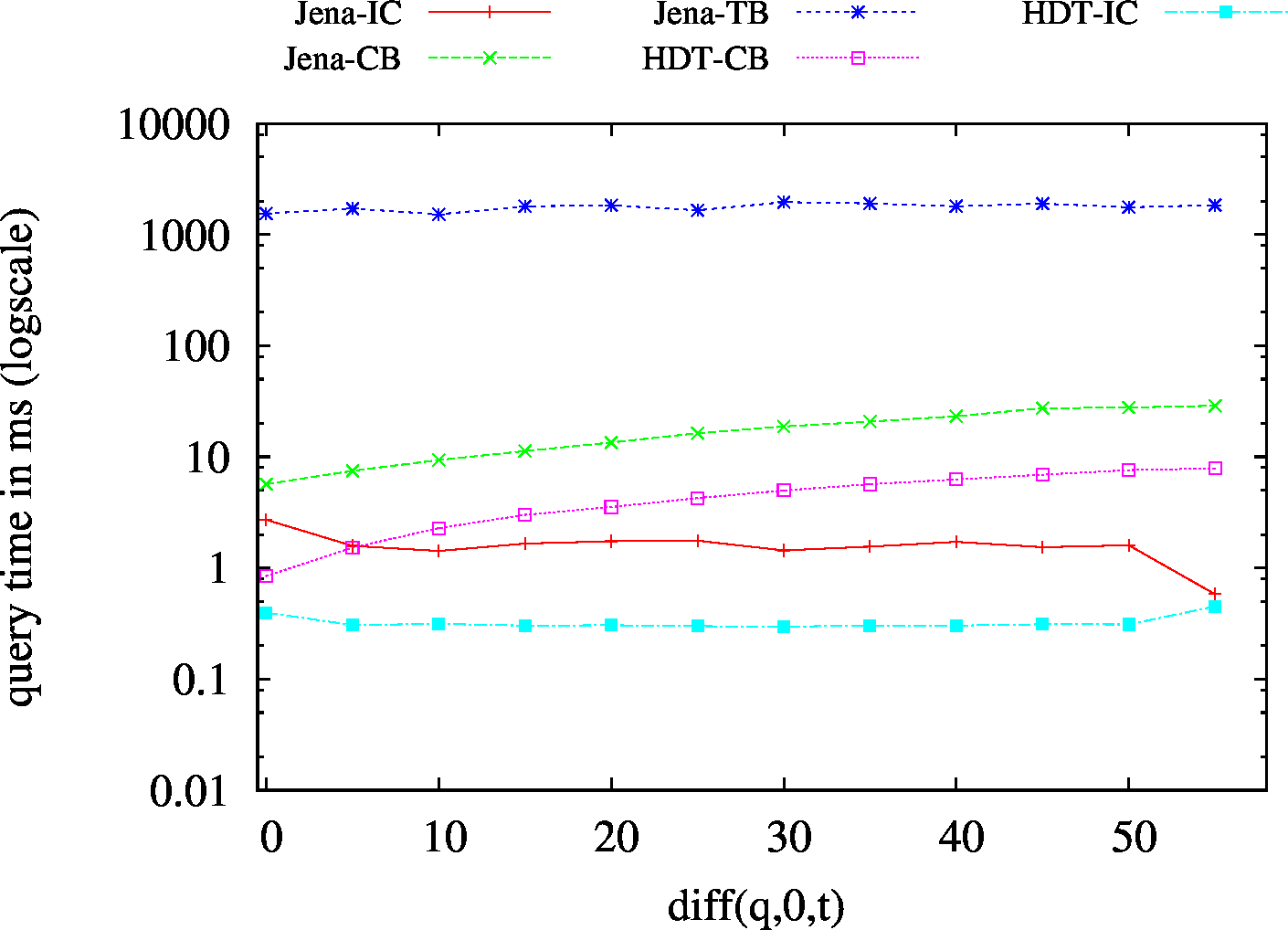
|
| SP? - Low Cardinality | SP? - High Cardinality |
|---|---|
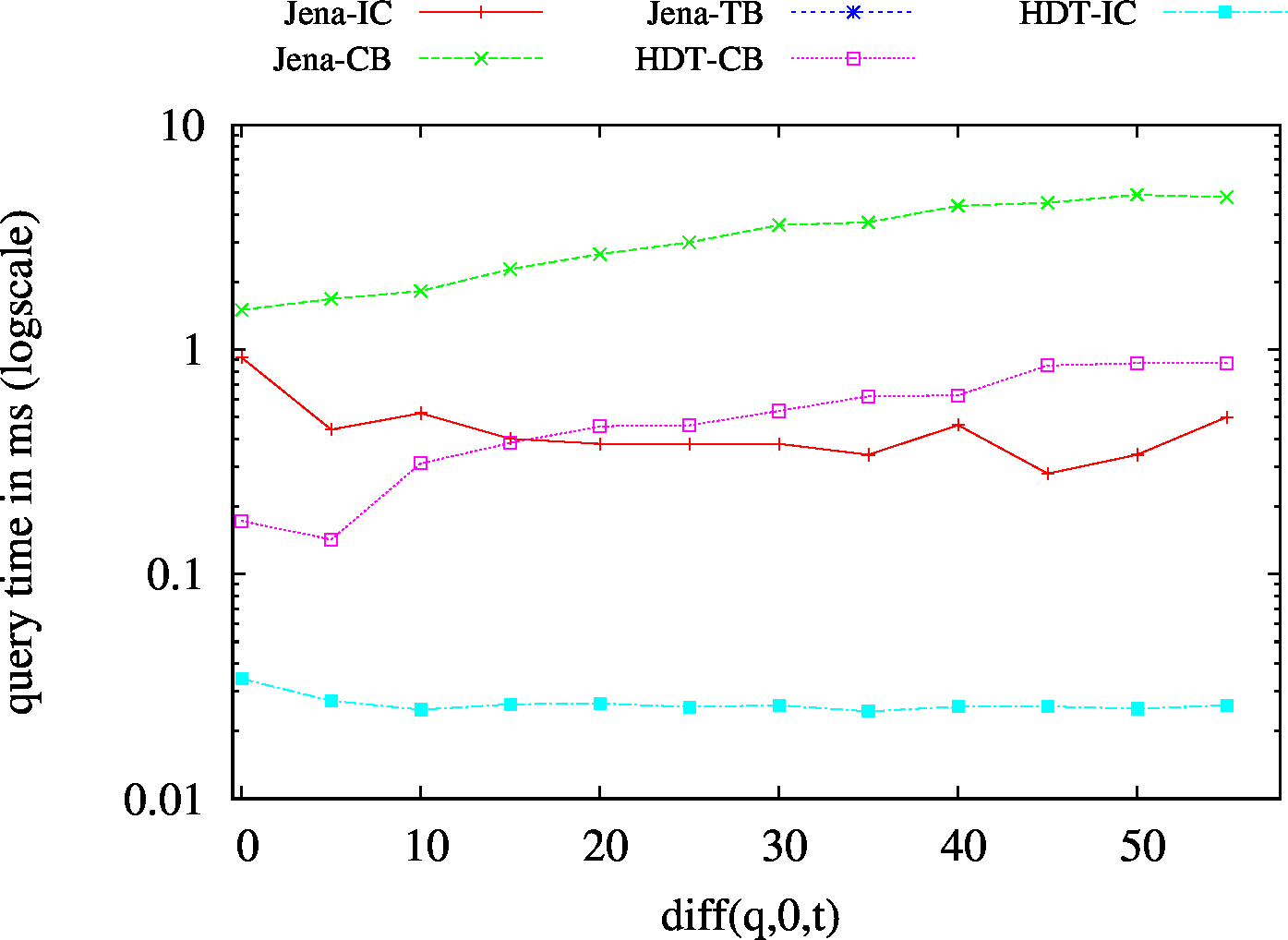
|
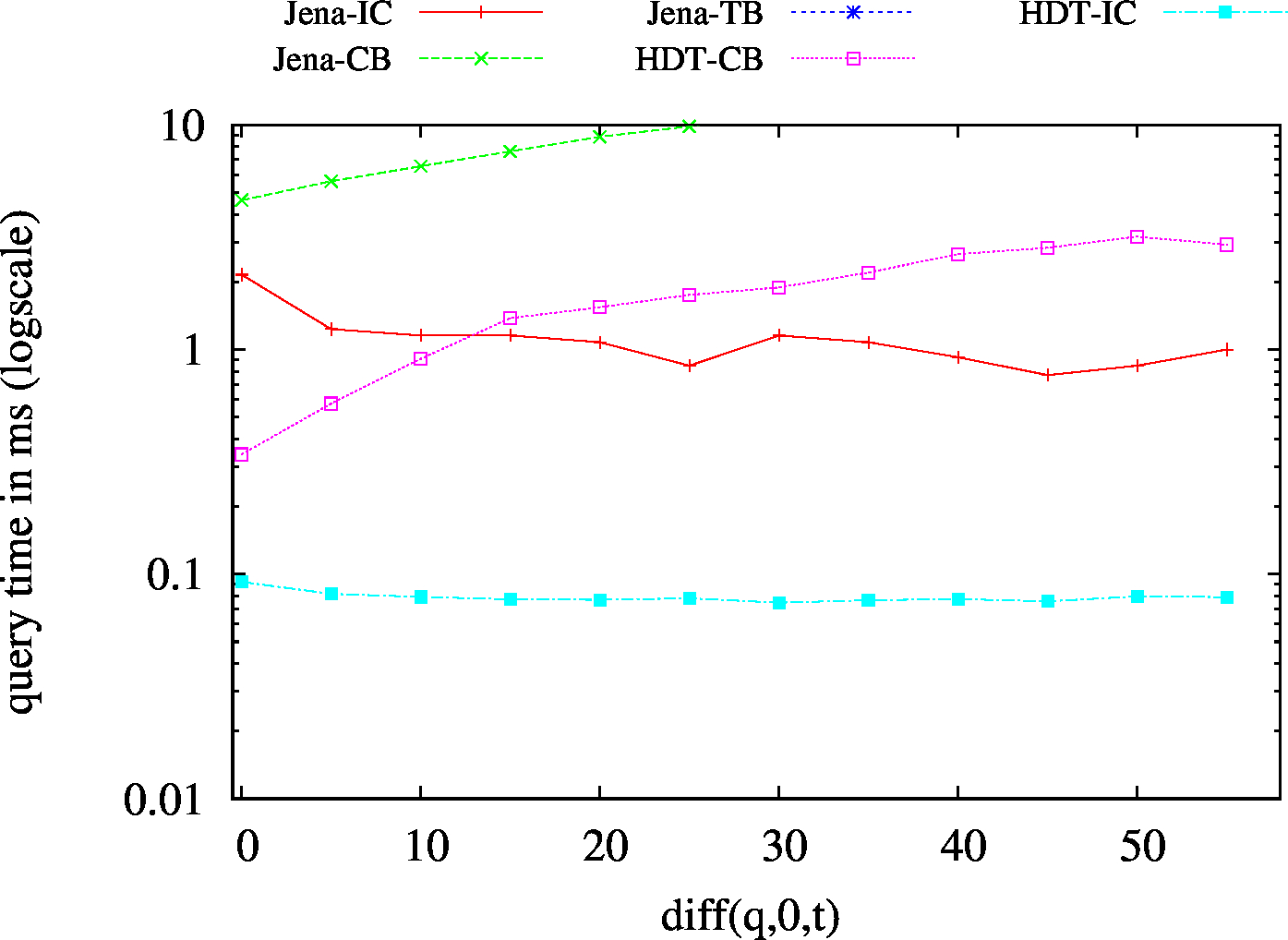
|
| ?PO - Low Cardinality | ?PO - High Cardinality |
|
|
| S?O - Low Cardinality | SPO |
|
|
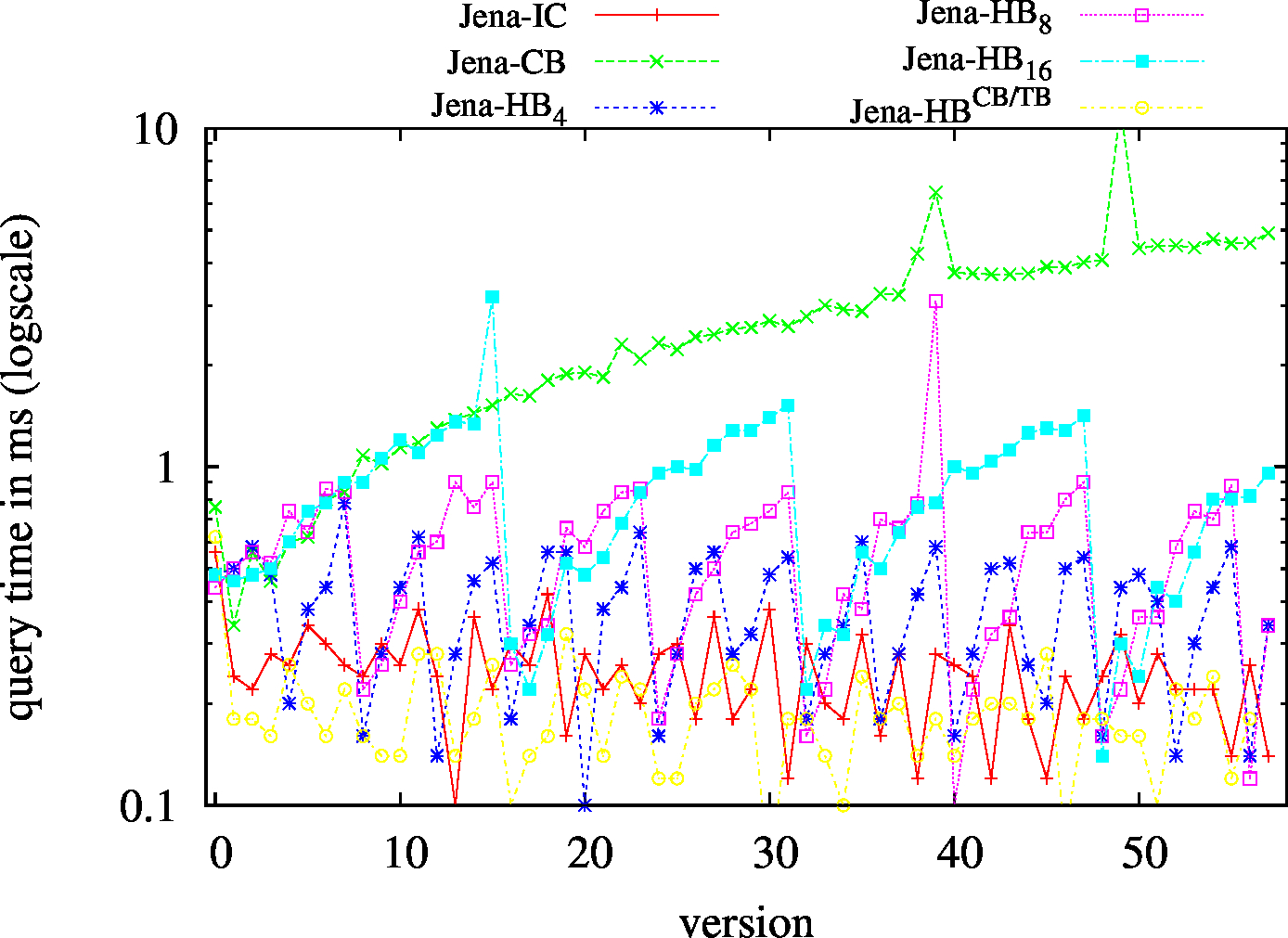
| S?? - Low Cardinality | S?? - High Cardinality |
|---|---|
|
|
| ?P? - Low Cardinality | ?P? - High Cardinality |
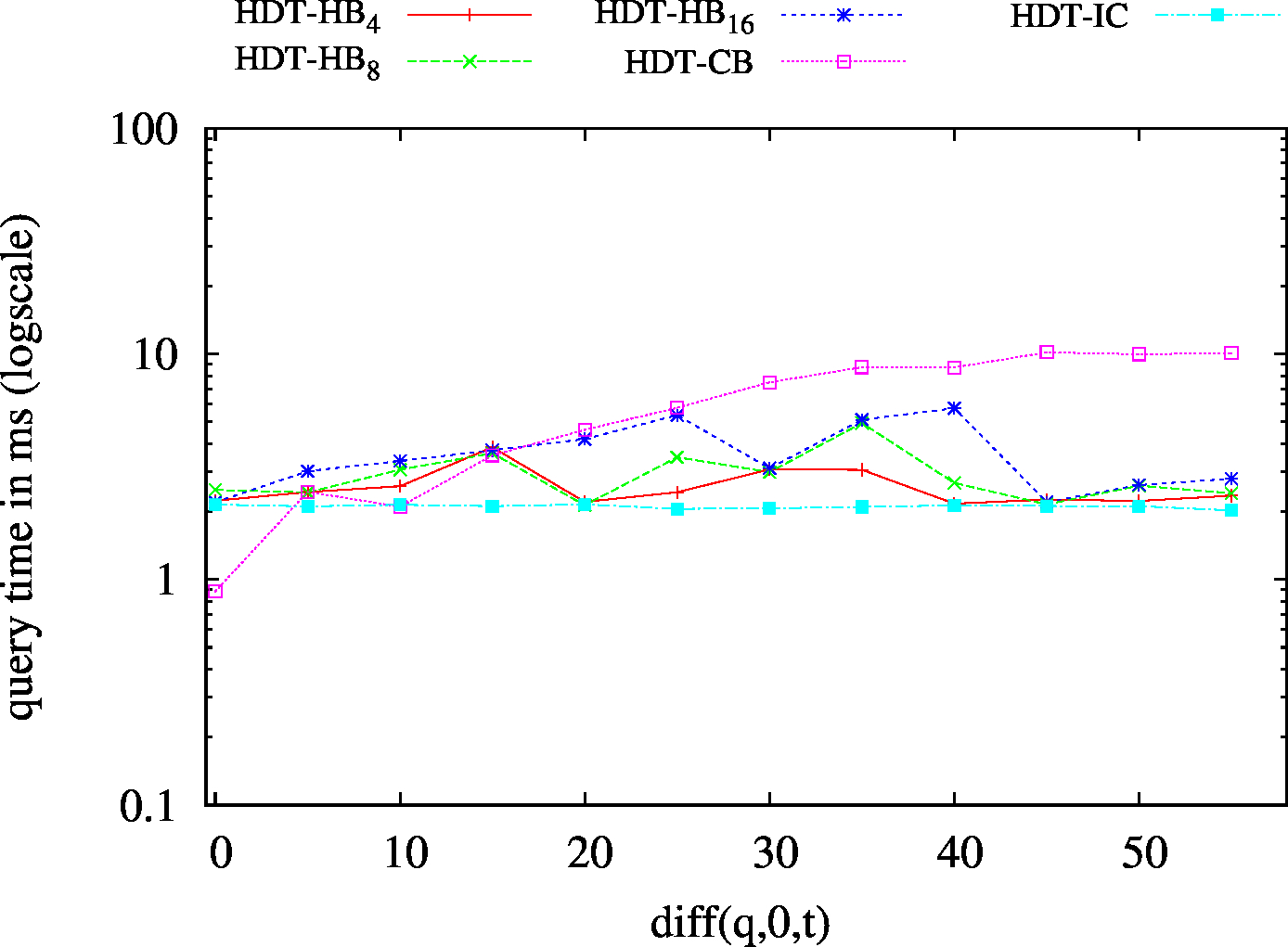
|
|
| ??O - Low Cardinality | ??O - High Cardinality |
|
|
| SP? - Low Cardinality | SP? - High Cardinality |
|---|---|
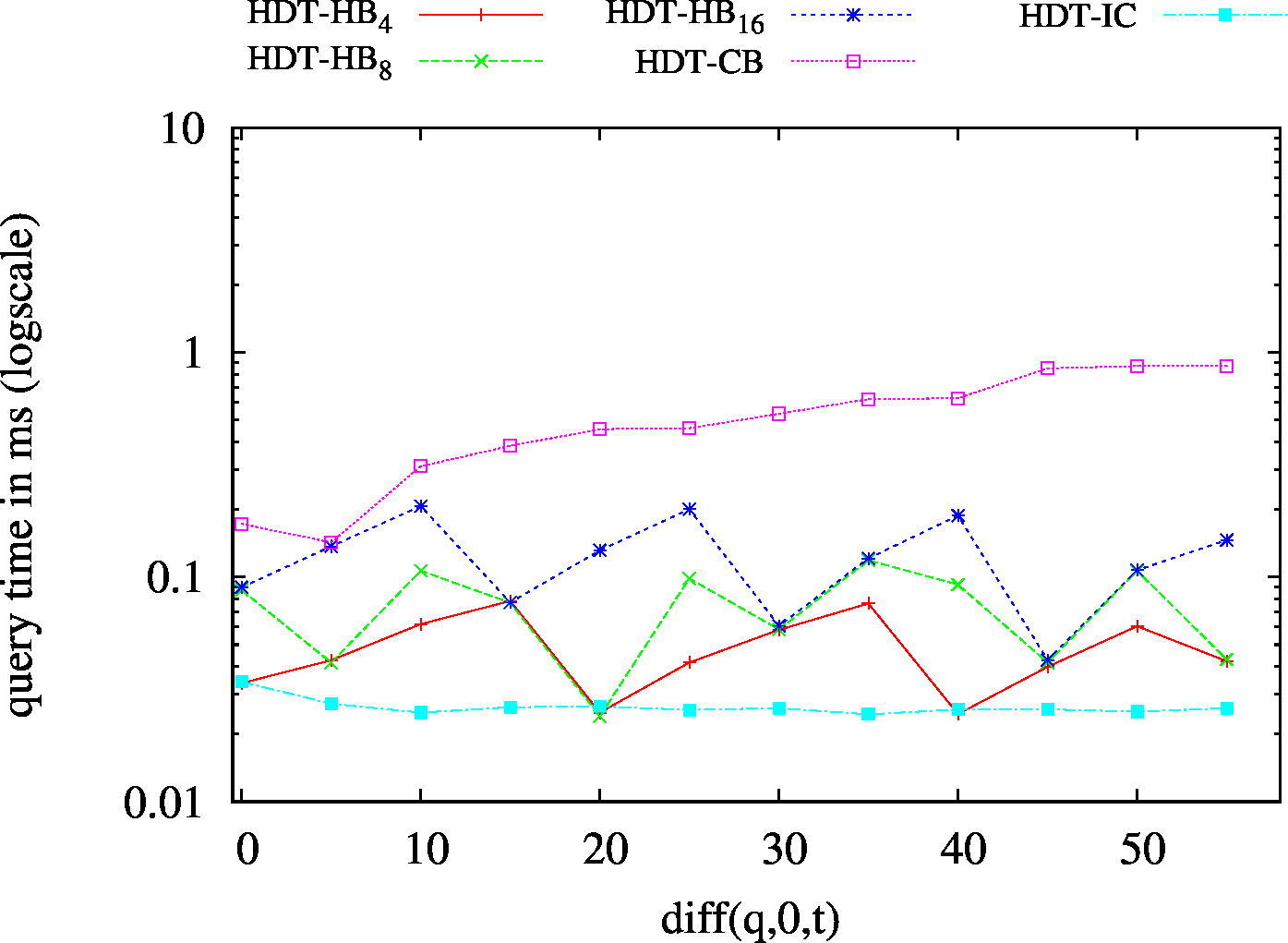
|
|
| ?PO - Low Cardinality | ?PO - High Cardinality |
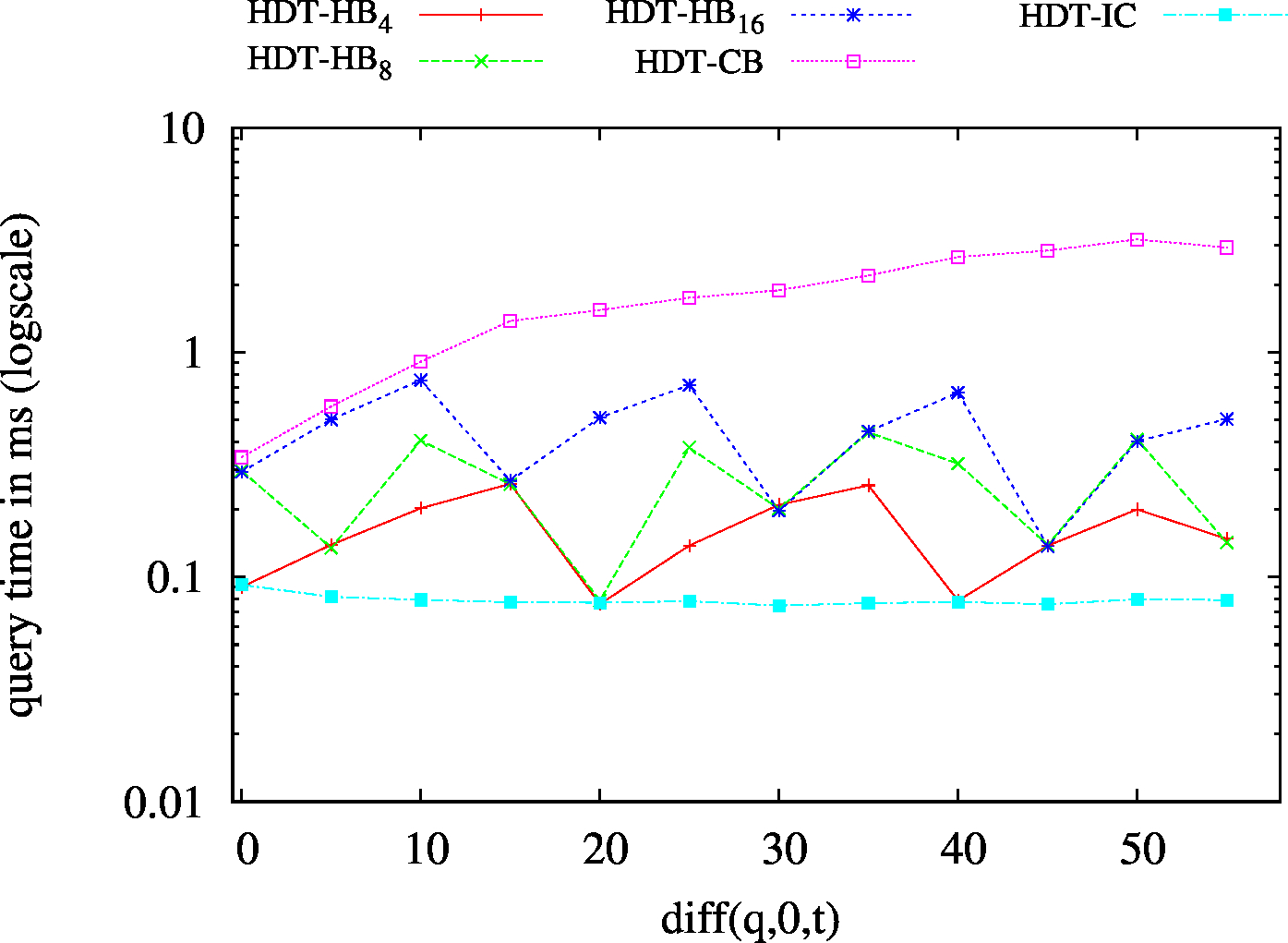
|

|
| S?O - Low Cardinality | SPO |
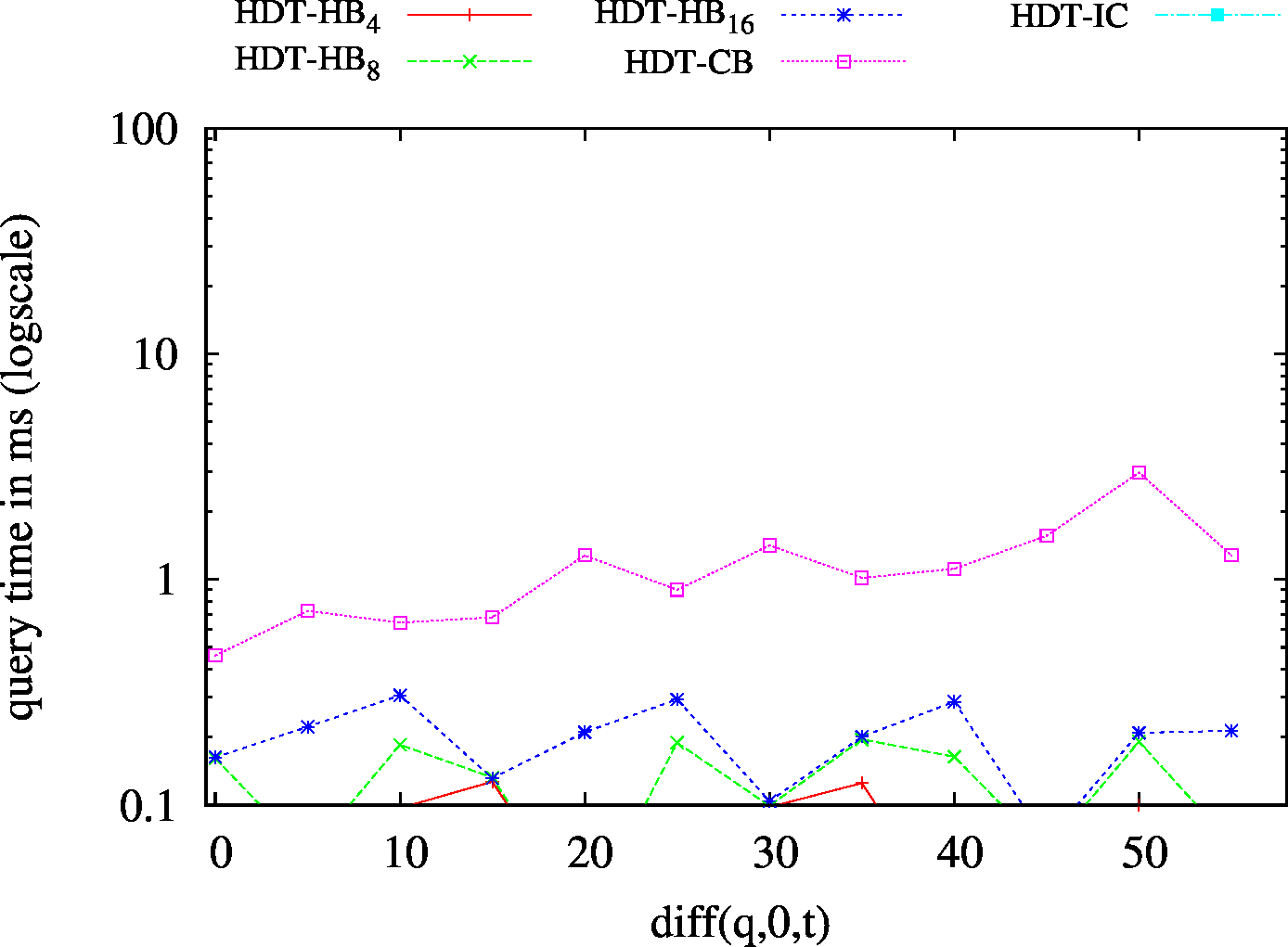
|
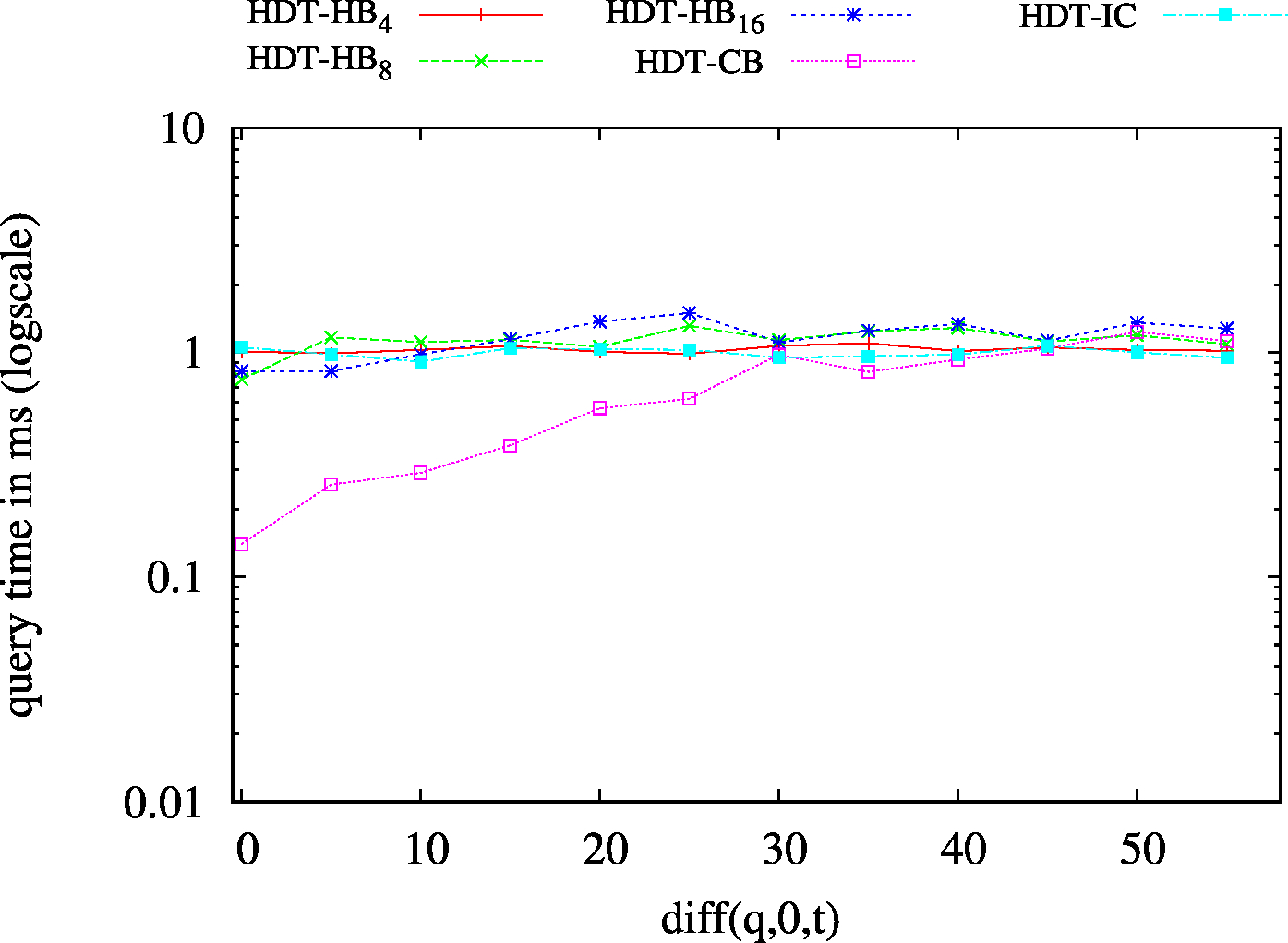
|
| S?? - Low Cardinality | S?? - High Cardinality |
|---|---|
|
|
| ?P? - Low Cardinality | ?P? - High Cardinality |
|
|
| ??O - Low Cardinality | ??O - High Cardinality |
|
|
| SP? - Low Cardinality | SP? - High Cardinality |
|---|---|
|
|
| ?PO - Low Cardinality | ?PO - High Cardinality |
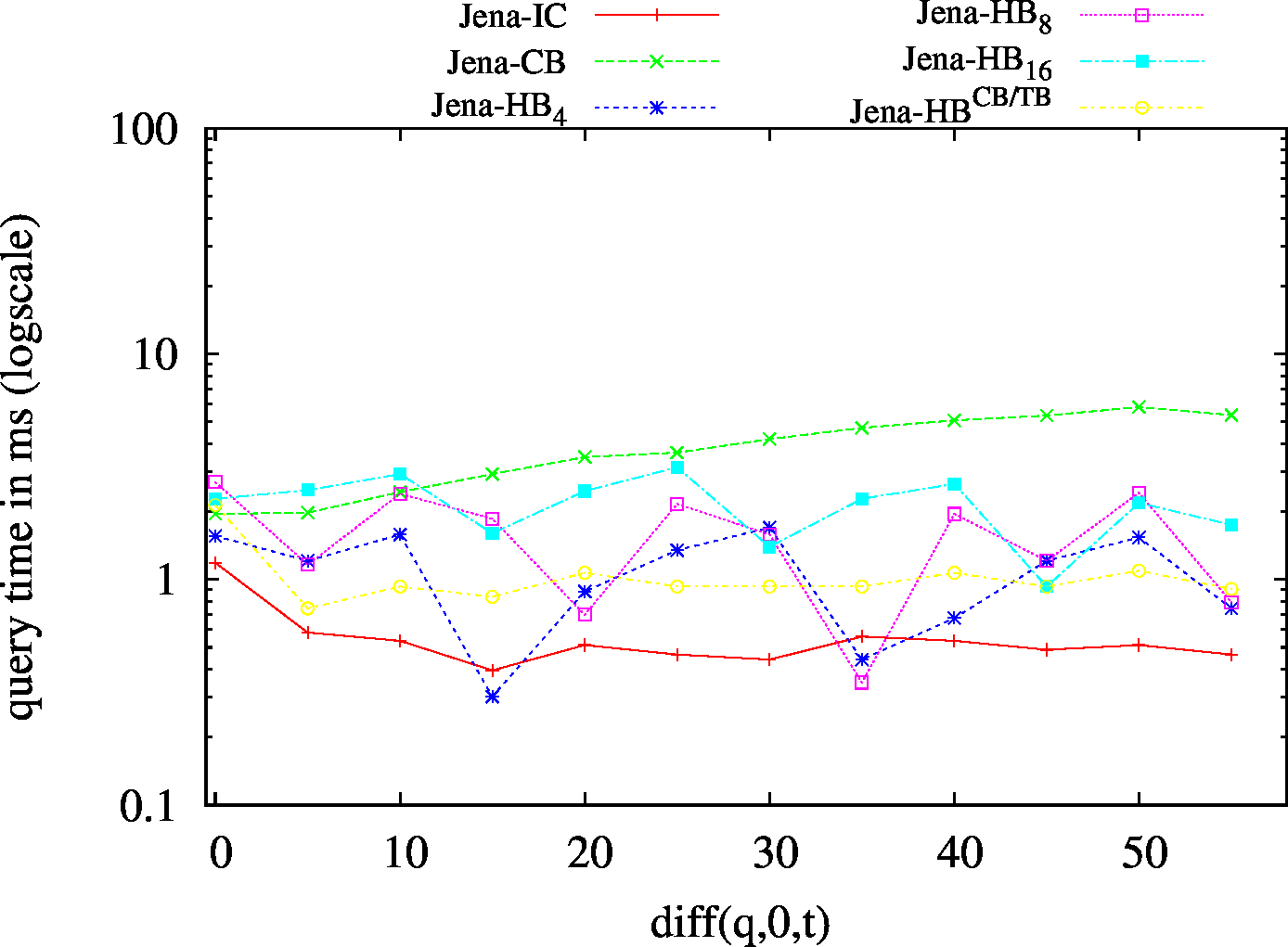
|
|
| S?O - Low Cardinality | SPO |
|
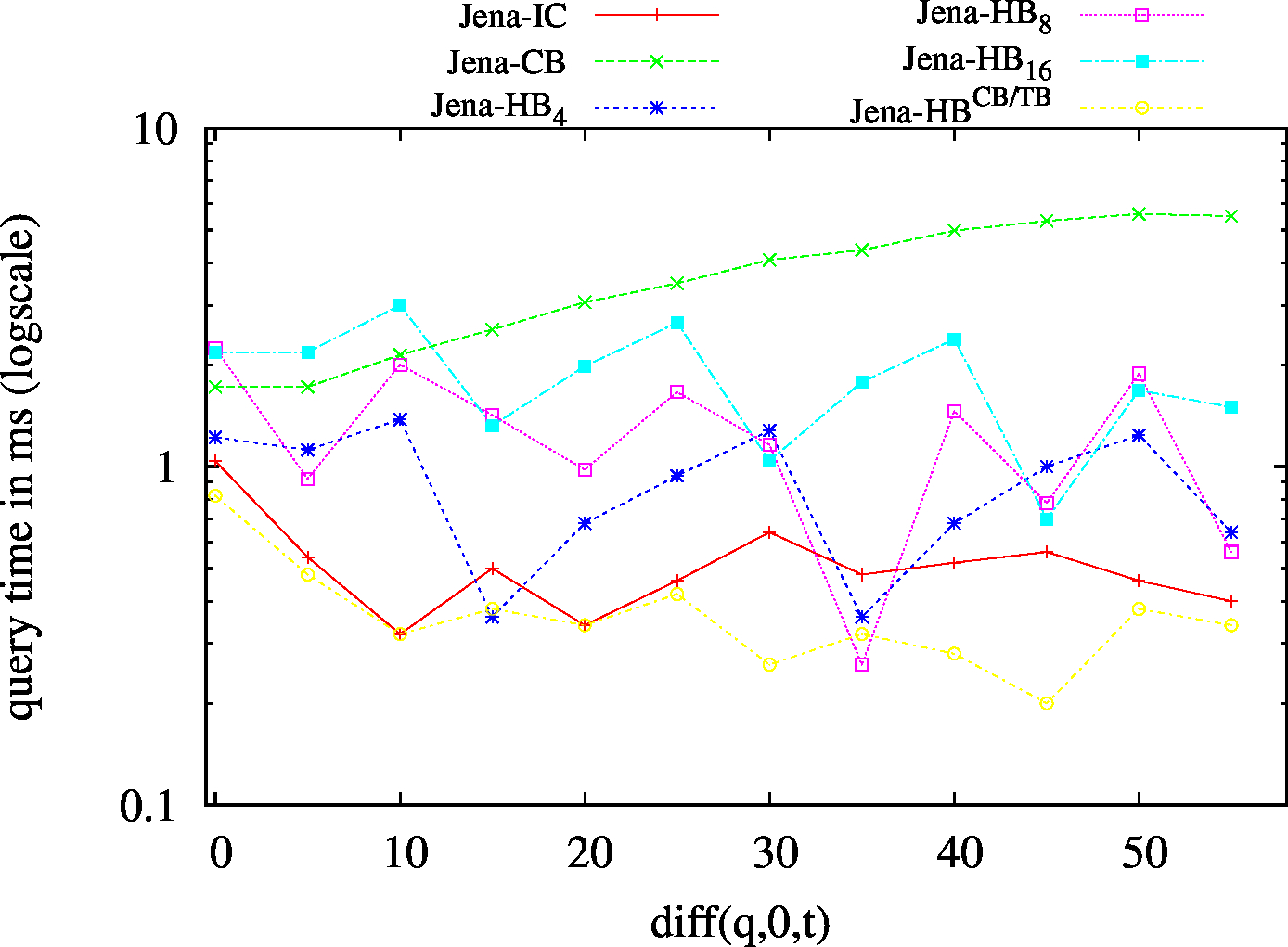
|
| Dataset | Jena TDB | HDT | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IC | CB | TB | Hybrid | IC | CB | Hybrid | ||||||||
| HBSIC/CB | HBMIC/CB | HBLIC/CB | HBTB/CB | HBSIC/CB | HBMIC/CB | HBLIC/CB | ||||||||
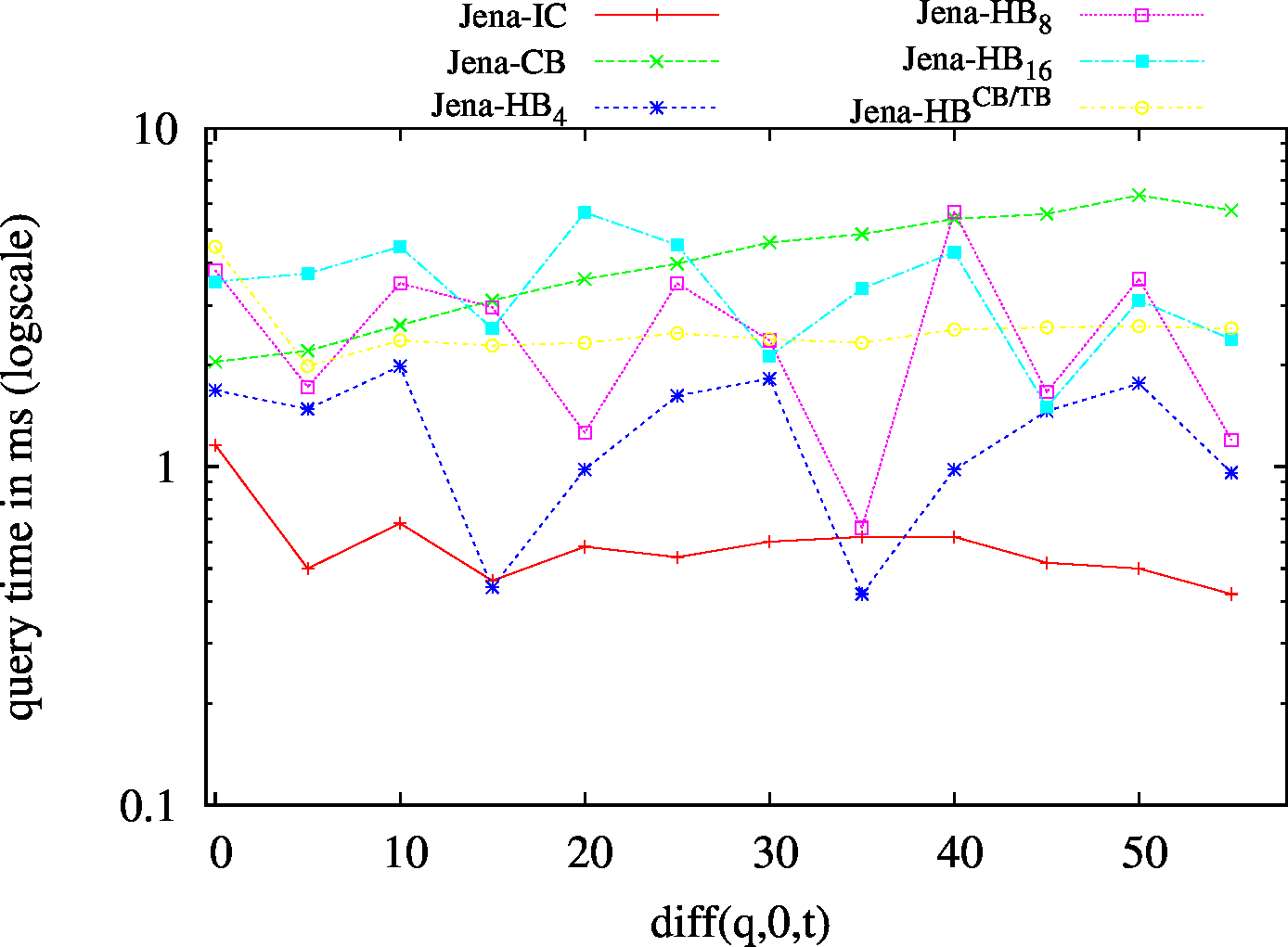
| (S??) Low Cardinality | 66 | 24 | 42732 | 24 | 31 | 32 | 7 | 1.54 | 1.91 | 2.30 | 2.47 | 2.64 | ||
| (S??) High Cardinality | 101 | 72 | 56693 | 76 | 75 | 89 | 44 | 4.98 | 7.98 | 10.94 | 13.59 | 18.32 | ||
| (?P?) Low Cardinality | 437 | 77 | 49411 | 115 | 130 | 115 | 79 | 42.88 | 13.79 | 30.97 | 29.03 | 31.71 | ||
| (?P?) High Cardinality | 809 | 205 | 54246 | 383 | 411 | 302 | 210 | 116.96 | 46.62 | 101.05 | 88.41 | 101.55 | ||
| (??O) Low Cardinality | 67 | 23 | 49424 | 23/td> | 23 | 45 | 6 | 1.44 | 2.36 | 2.96 | 2.85 | 2.91 | ||
| (??O) High Cardinality | 99 | 67 | 58114 | 80 | 74 | 74 | 54 | 7.12 | 11.73 | 14.28 | 16.40 | 20.18 | ||
| Dataset | Jena TDB | HDT | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IC | CB | TB | Hybrid | IC | CB | Hybrid | ||||||||
| HBSIC/CB | HBMIC/CB | HBLIC/CB | HBTB/CB | HBSIC/CB | HBMIC/CB | HBLIC/CB | ||||||||
| (SP?) Low Cardinality | 53 | 15 | 55283 | 15 | 15 | 16 | 1 | 0.83 | 1.02 | 1.07 | 1.15 | 1.13 | ||
| (SP?) High Cardinality | 67 | 50 | 57720 | 45 | 50 | 50 | 17 | 1.75 | 3.88 | 4.48 | 4.69 | 5.59 | ||
| (?PO) Low Cardinality | 57 | 21 | 56151 | 20 | 20 | 21 | 3 | 1.32 | 2.04 | 2.01 | 2.03 | 2.15 | ||
| (?PO) High Cardinality | 136 | 116 | 59831 | 113 | 107 | 121 | 92 | 11.58 | 20.91 | 24.82 | 29.74 | 38.39 | ||
| (S?O) Low Cardinality | 55 | 16 | 45193 | 19/td> | 17 | 18 | 1 | 1.36 | 1.78 | 2.02 | 1.73 | 1.73 | ||
| (SPO) | 54 | 17 | 50393 | 16 | 17 | 17 | 1 | 18.35 | 3.37 | 11.14 | 9.17 | 8.00 | ||
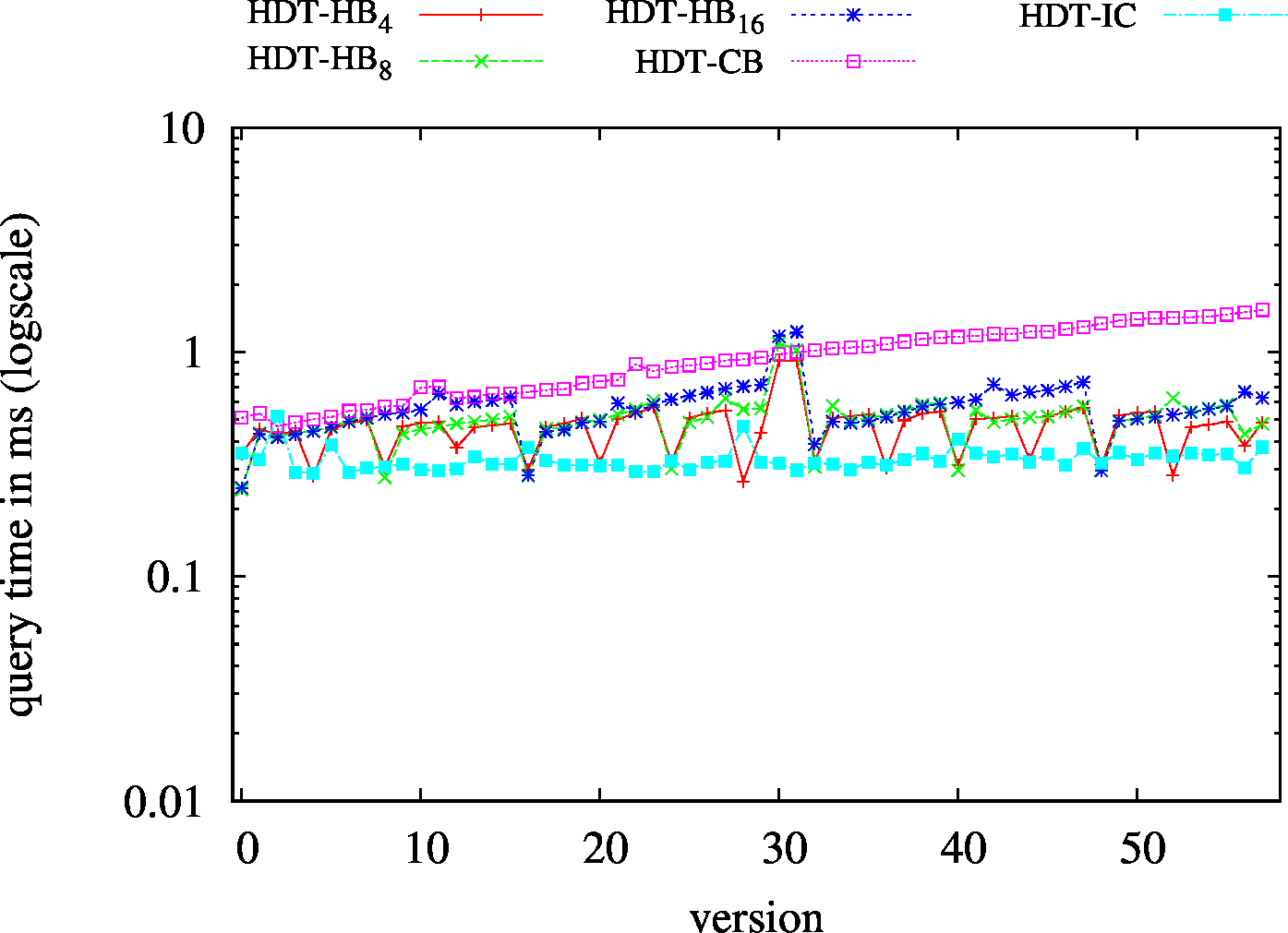
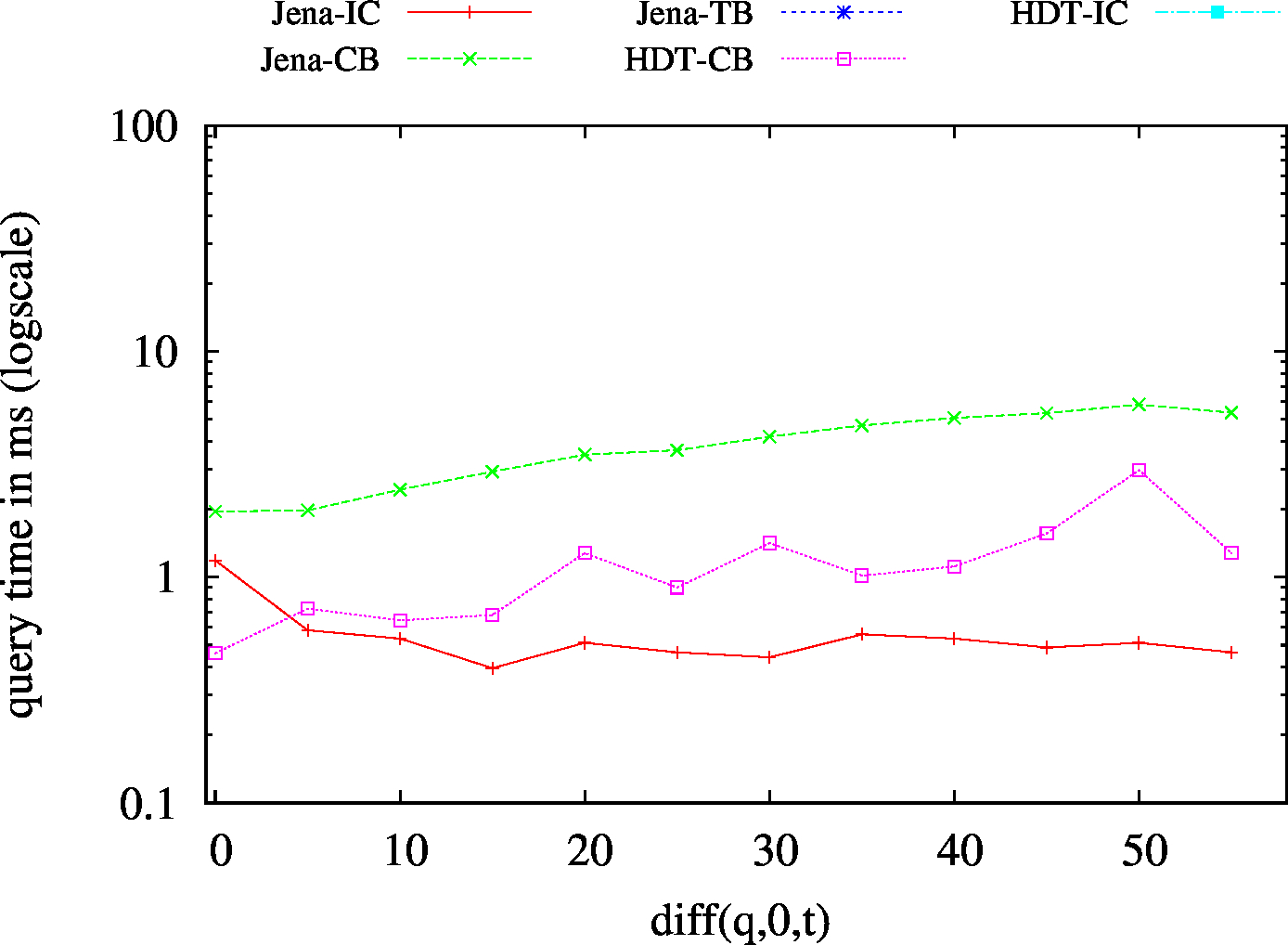
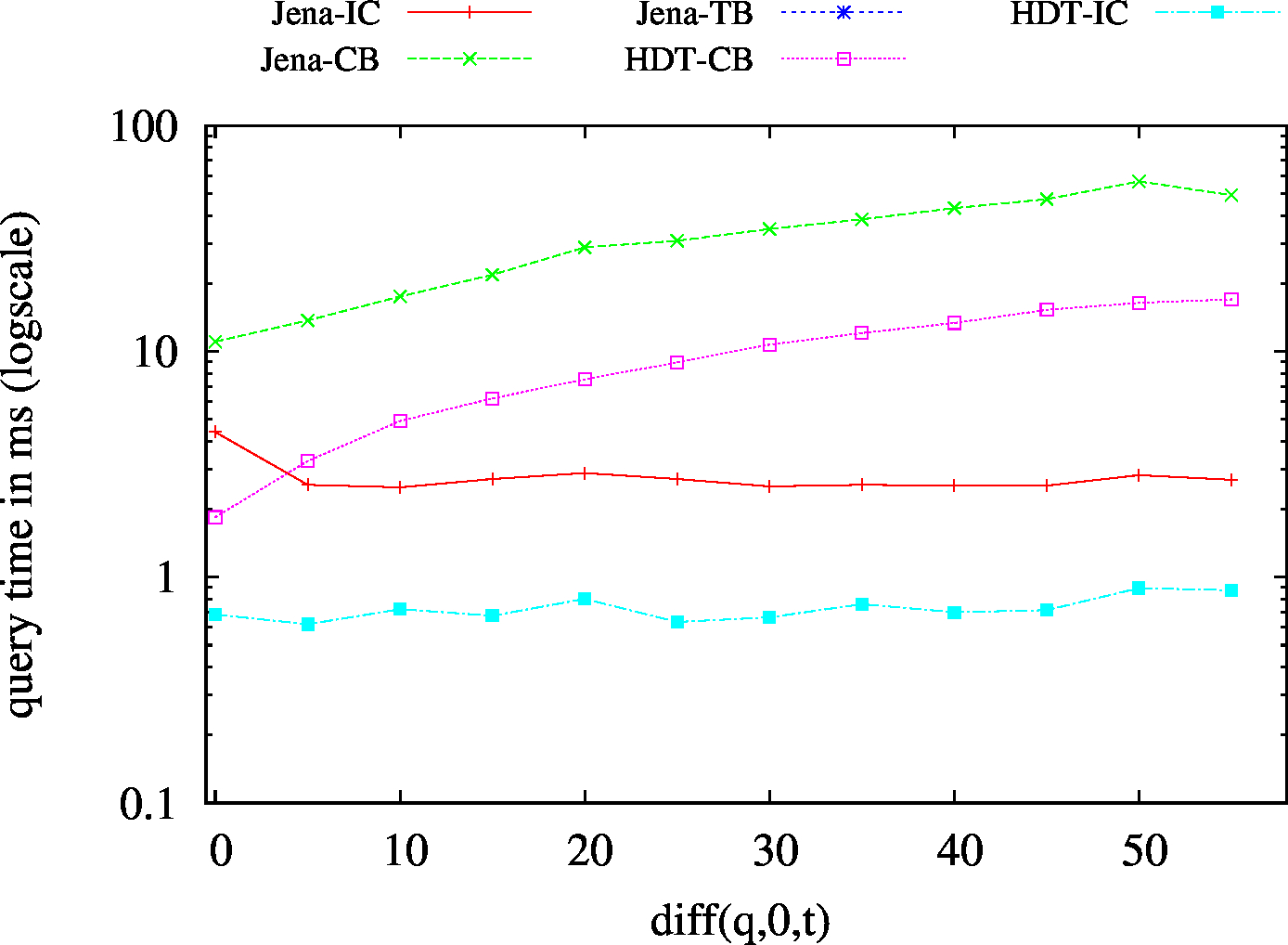
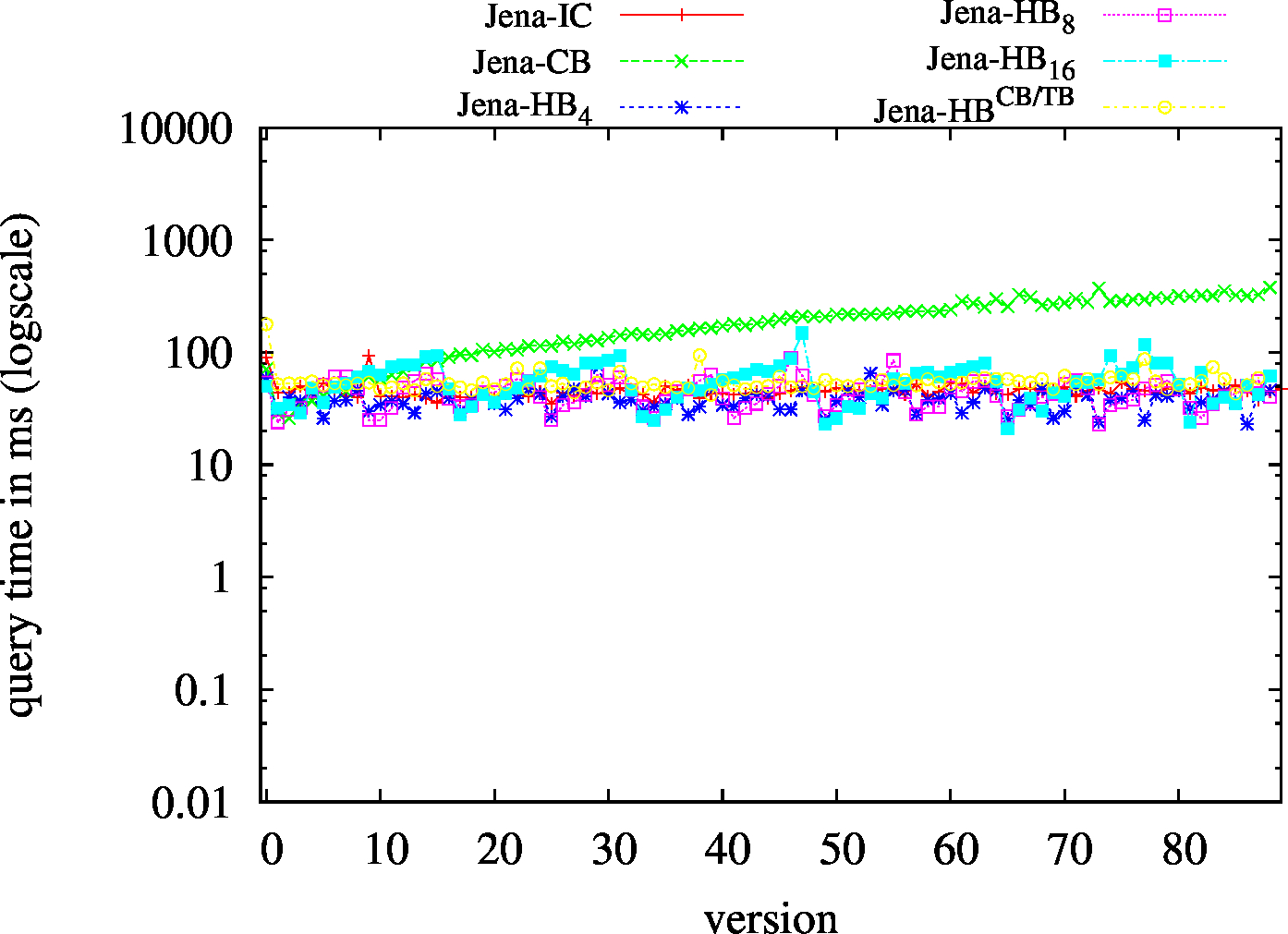
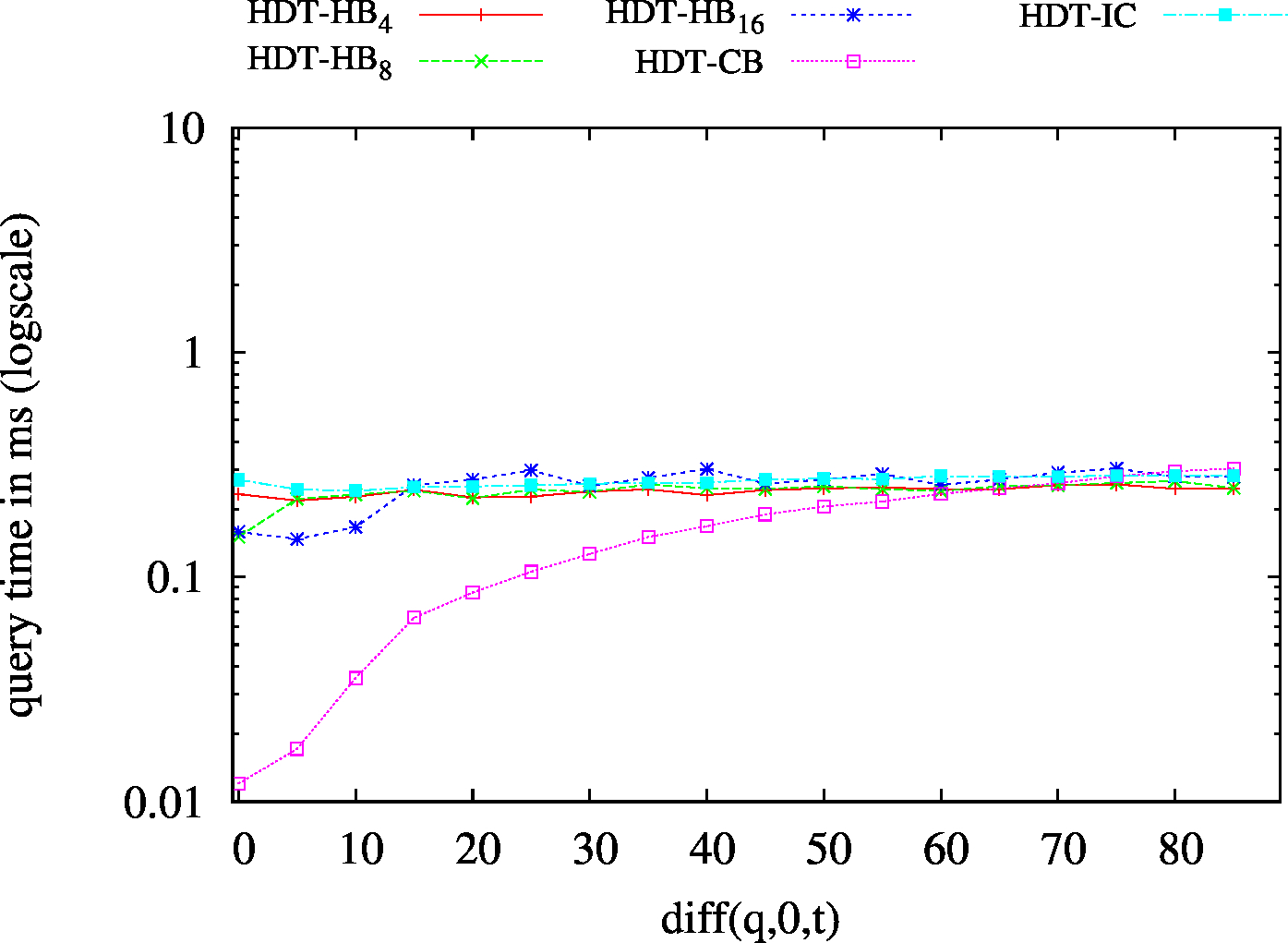
| BEAR-B-day | BEAR-B-hour |
|---|---|
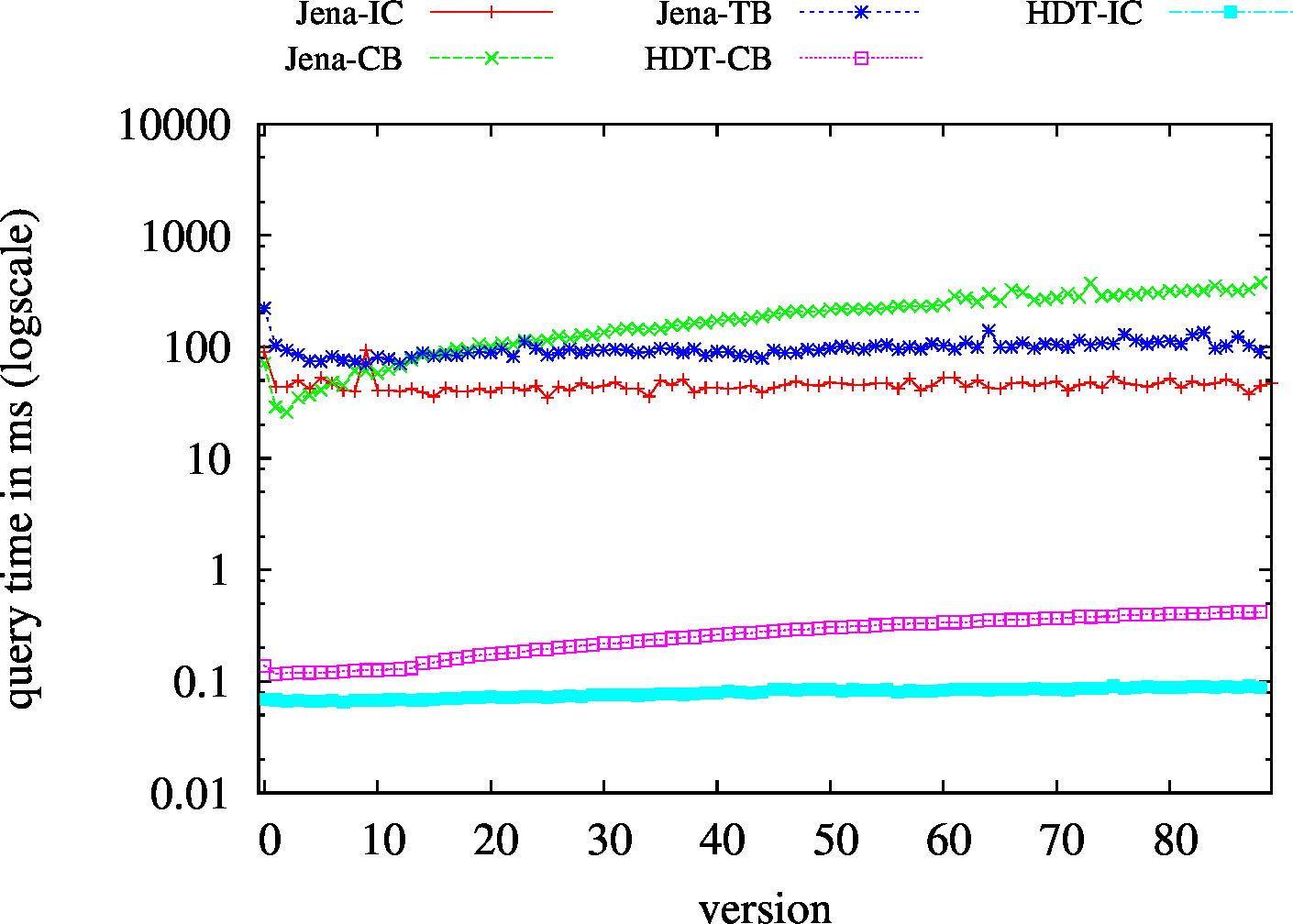
|
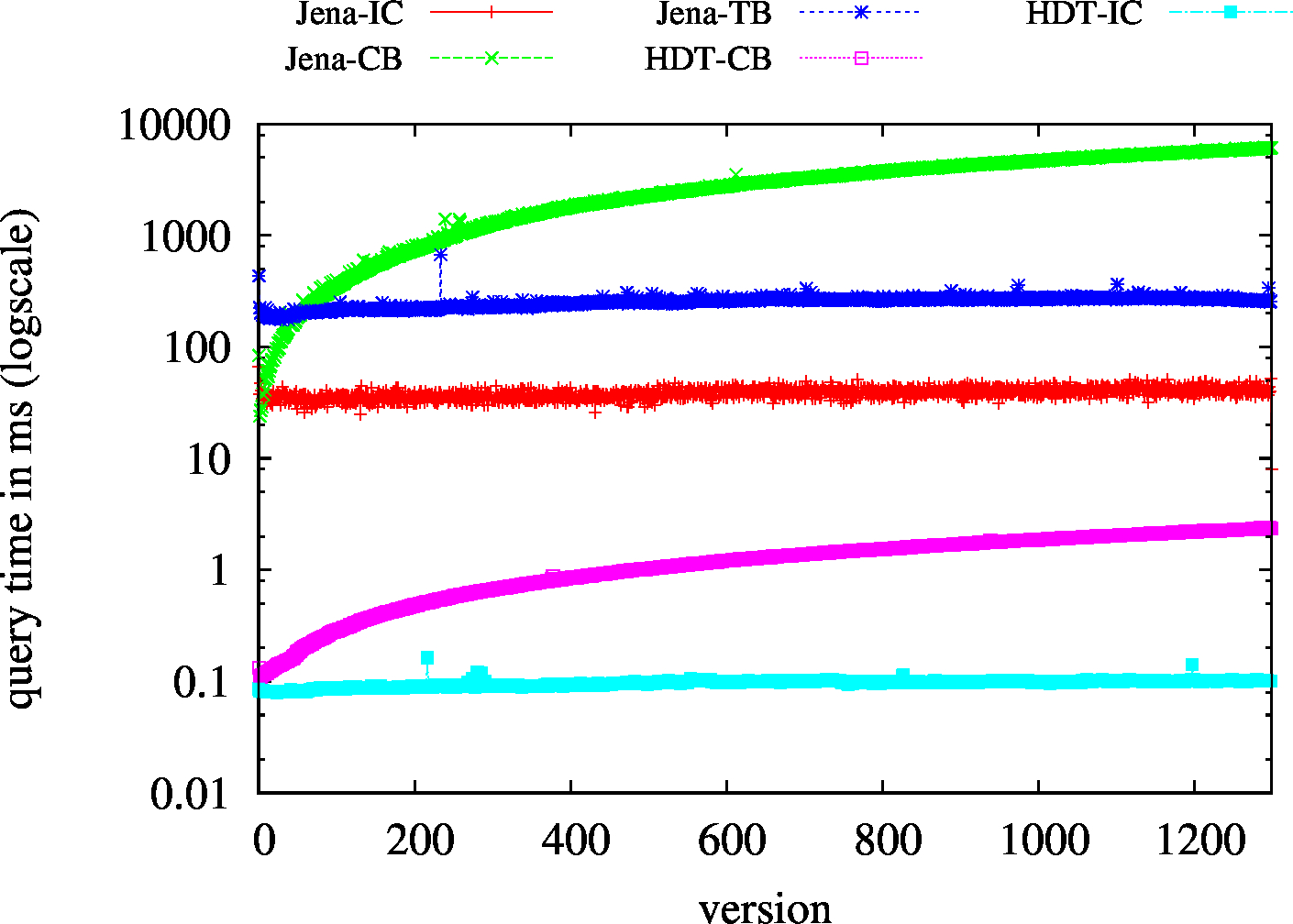
|
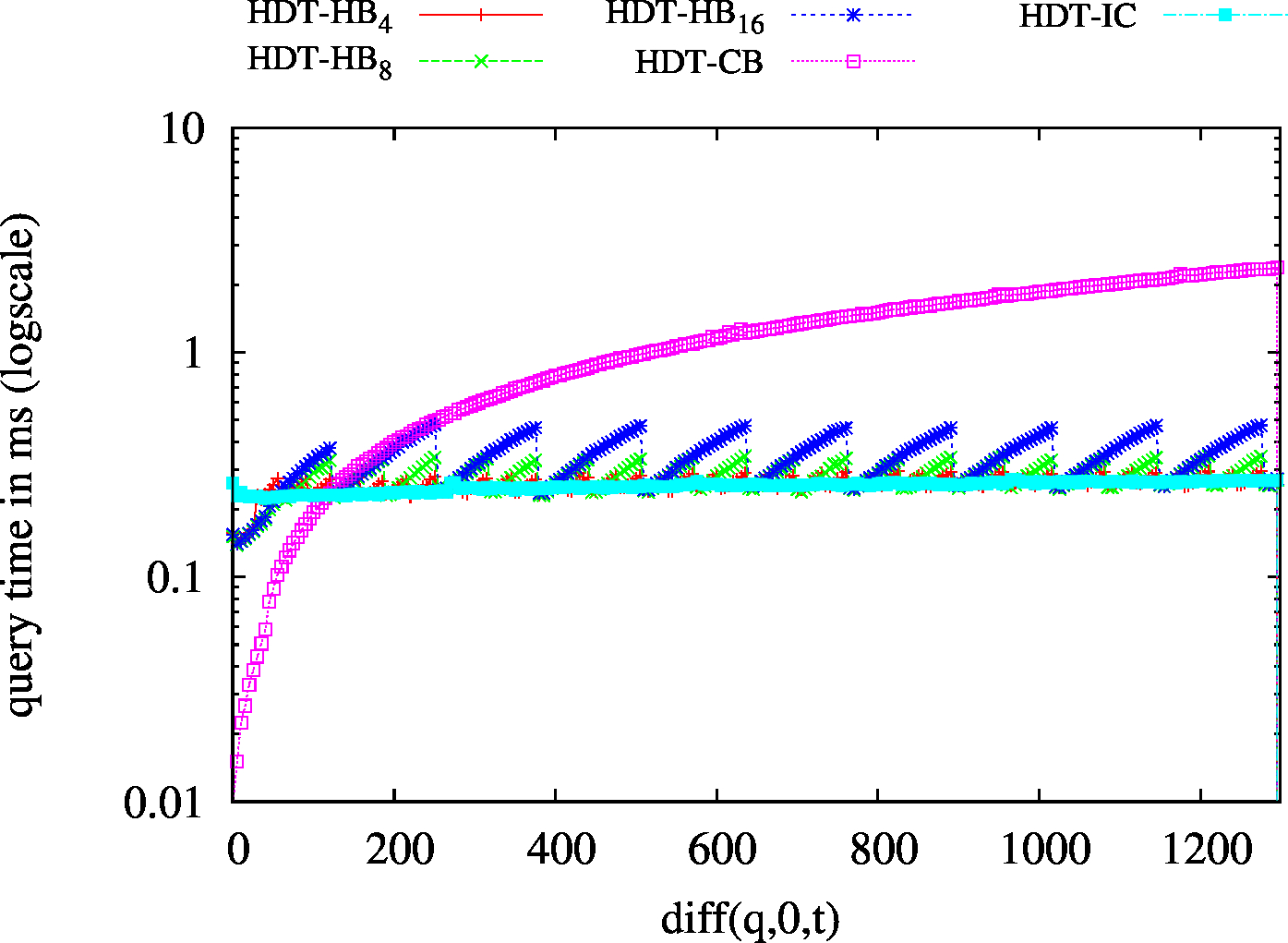
| BEAR-B-day | BEAR-B-hour |
|---|---|
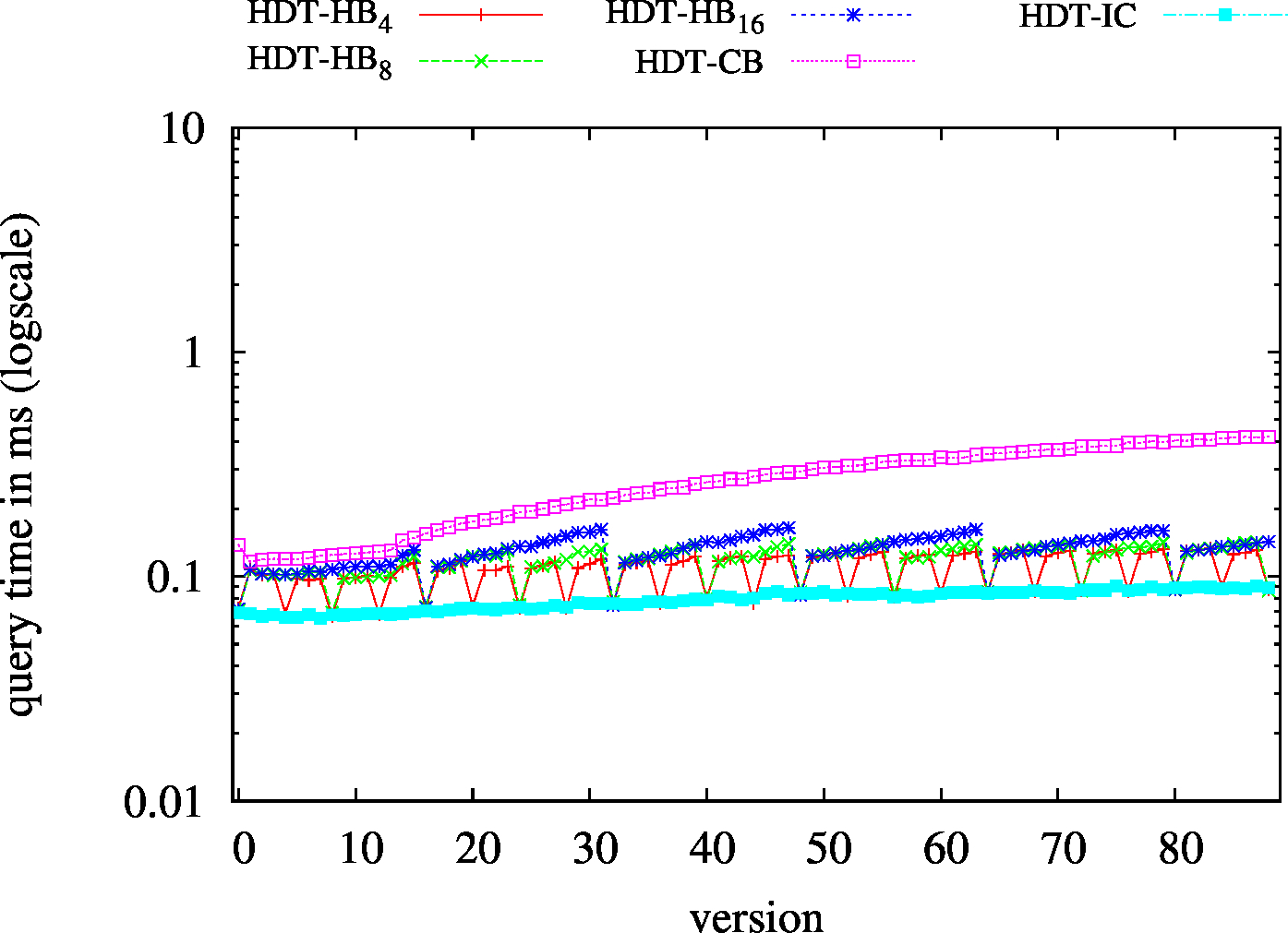
|
|
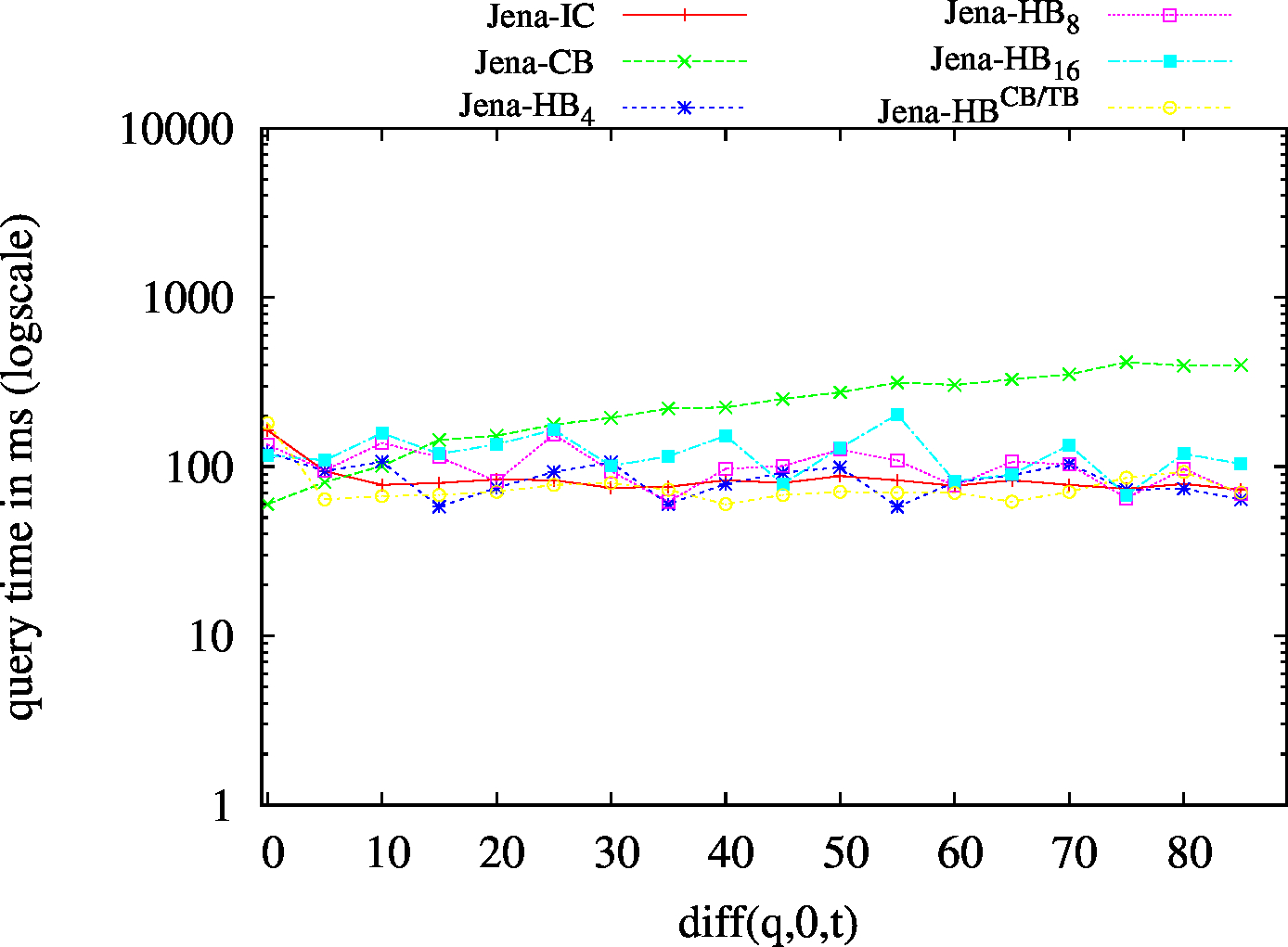
| BEAR-B-day | BEAR-B-hour |
|---|---|
|
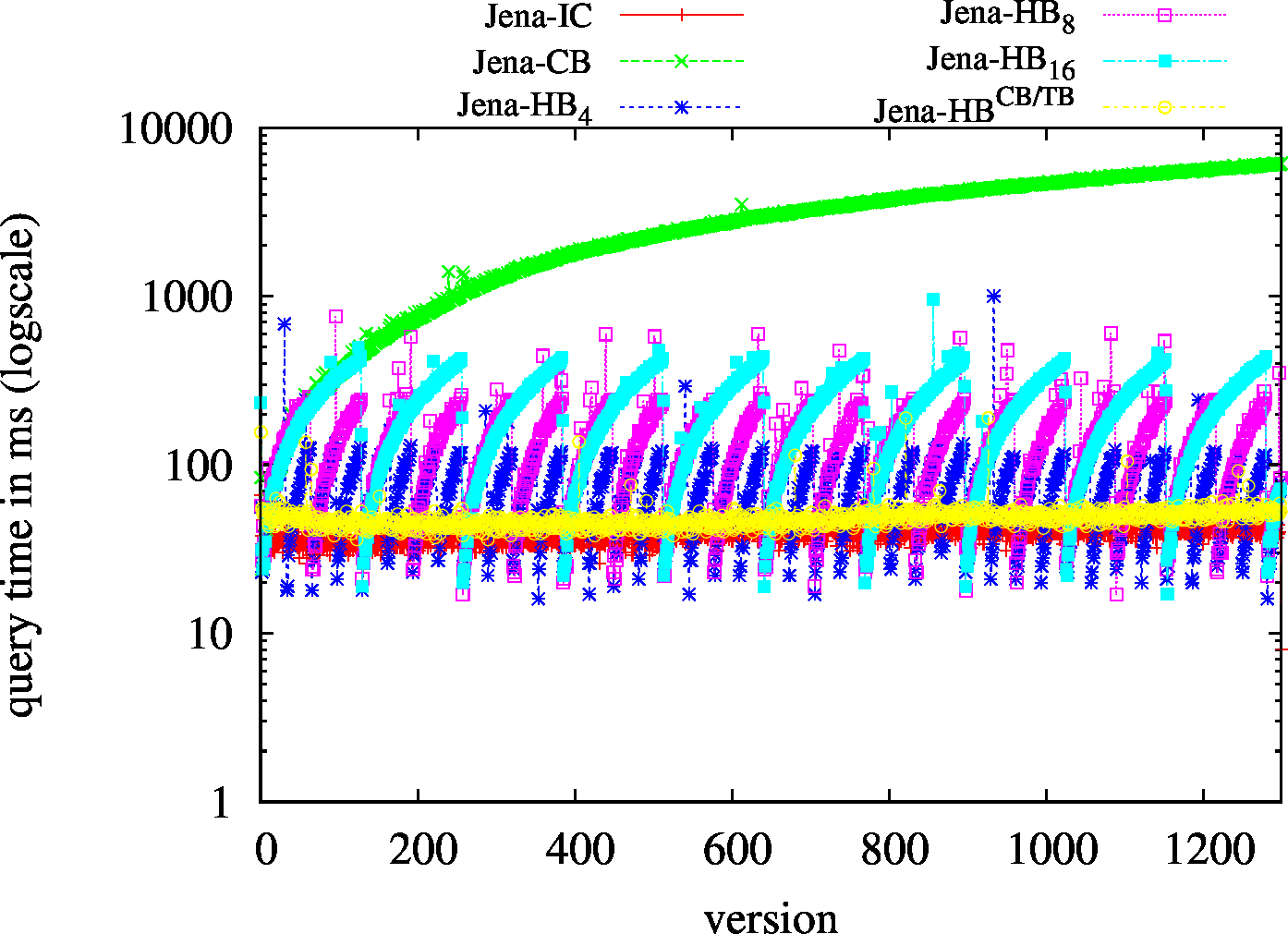
|
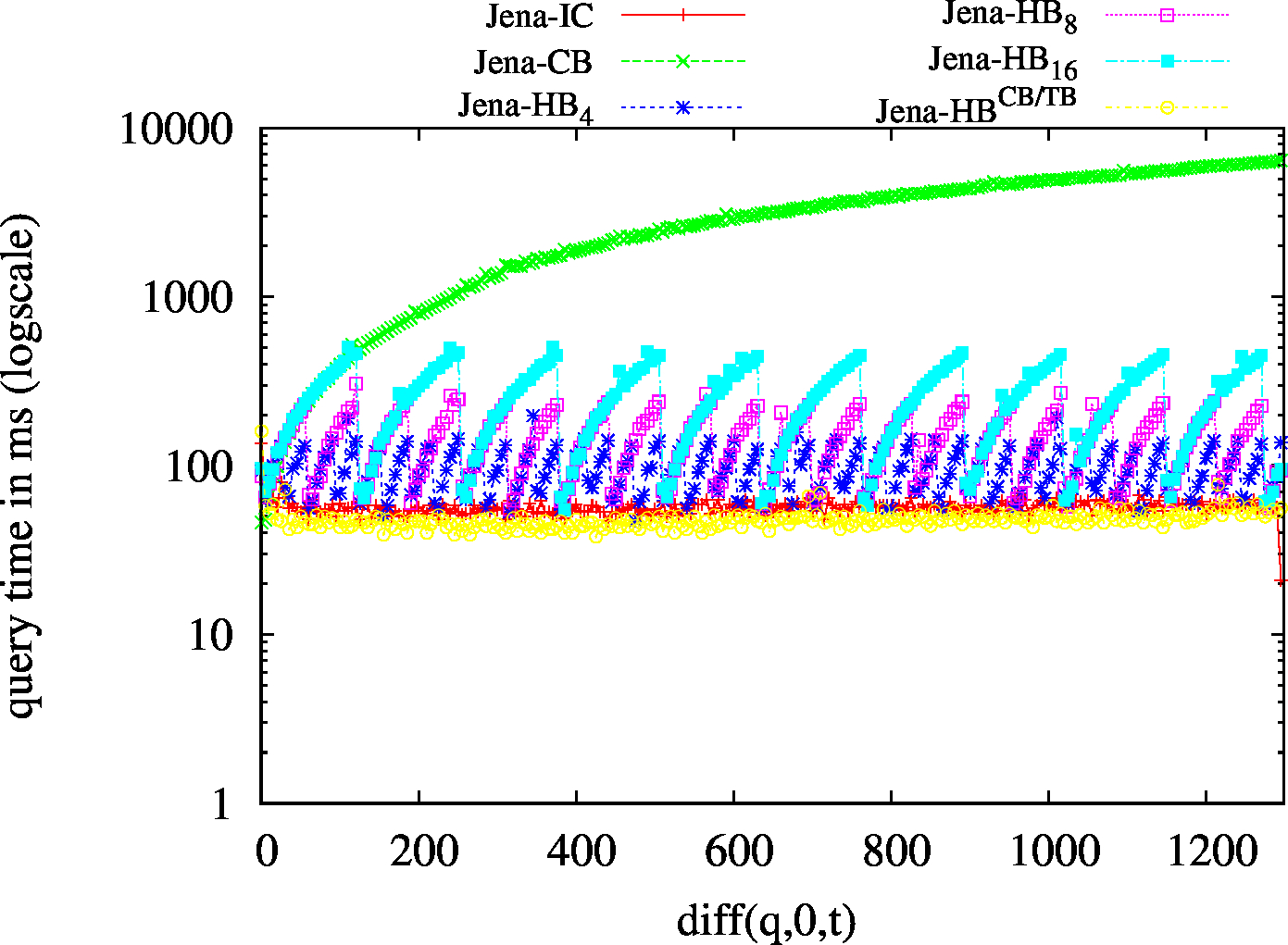
| BEAR-B-day | BEAR-B-hour |
|---|---|
|

|
| BEAR-B-day | BEAR-B-hour |
|---|---|
|
|
| BEAR-B-day | BEAR-B-hour |
|---|---|
|
|
| Dataset | Jena TDB | HDT | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IC | CB | TB | Hybrid | IC | CB | Hybrid | ||||||
| HBSIC/CB | HBMIC/CB | HBLIC/CB | HBTB/CB | HBSIC/CB | HBMIC/CB | HBLIC/CB | ||||||
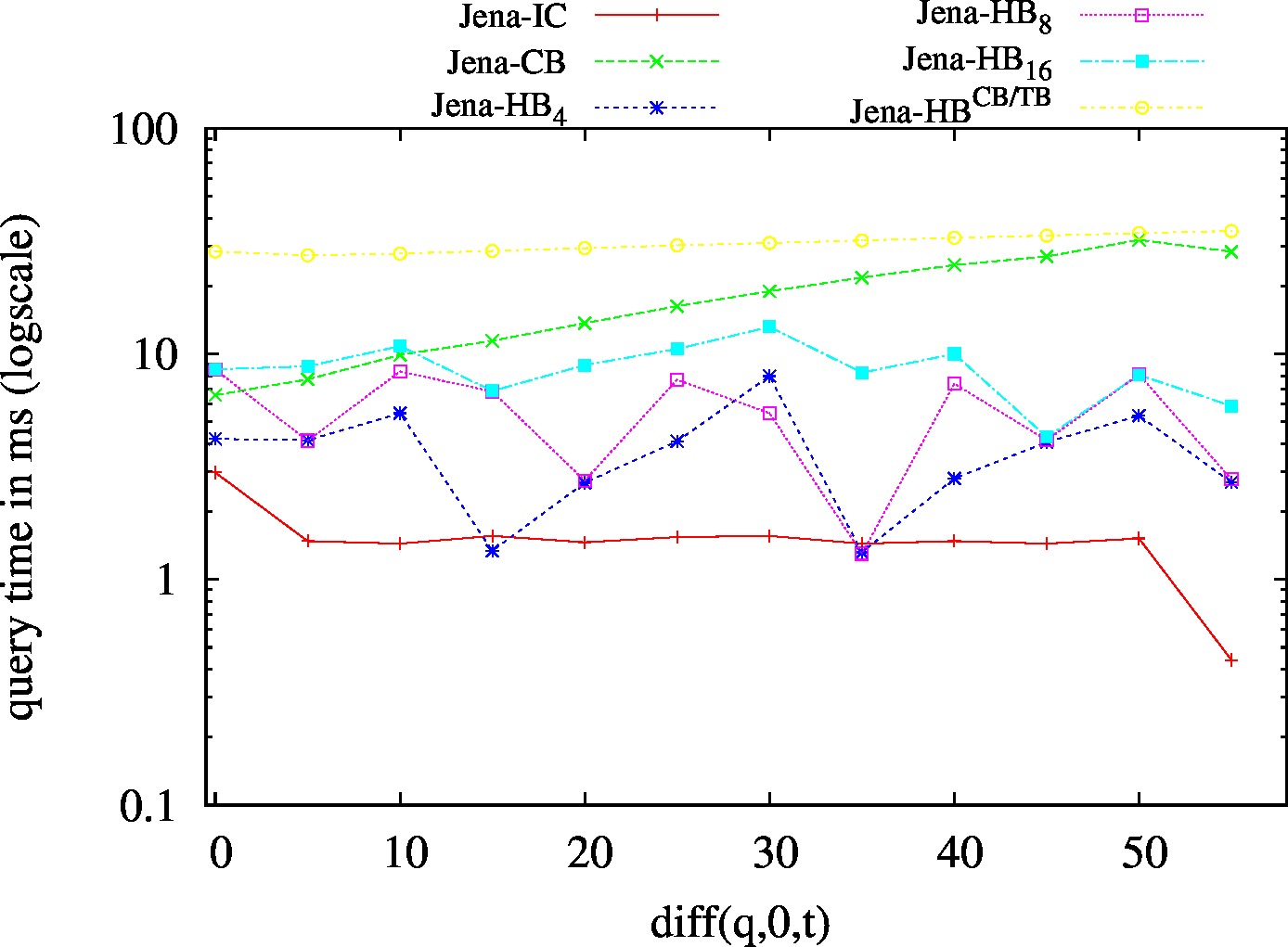
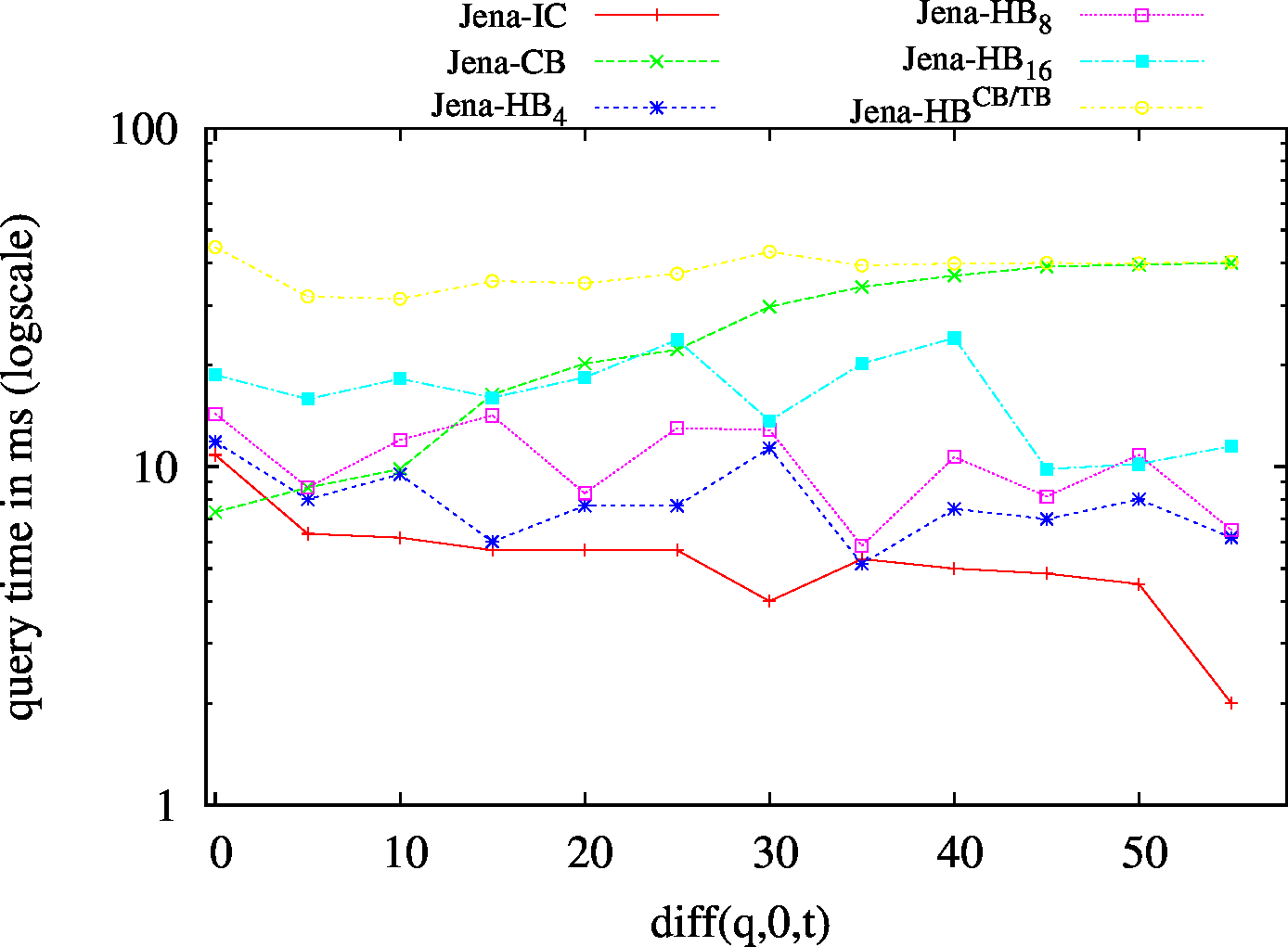
| BEAR-B-day | 83 | 19 | 1775 | 32 | 25 | 23 | 6 | 6.57 | 0.43 | 3.64 | 2.43 | 1.78 |
| BEAR-B-hour | 1189 | 120 | 6473 | 147 | 138 | 132 | 24 | 111.61 | 2.49 | 18.60 | 17.26 | 20.45 |
[1] Fernández, J. D., Umbrich, J., Polleres, A., & Knuth, M. (Under review). Evaluating Query and Storage Strategies for RDF Archives. Semantic Web Journal.
Under review. Available here.
[2] Fernández, J. D., Umbrich, J., Polleres, A., & Knuth, M. (2016, September). Evaluating Query and Storage Strategies for RDF Archives. In Proceedings of the 12th International Conference on Semantic Systems (pp. 41-48). ACM.
Bibtex | PDF
Funded by Austrian Science Fund (FWF): M1720- G11, European Union’s Horizon 2020 research and innovation programme under grant 731601 (SPECIAL), MINECO-AEI/FEDER-UE ETOME-RDFD3: TIN2015-69951-R, by Austrian Research Promotion Agency (FFG): grant no. 849982 (ADEQUATe) and grant 861213 (CitySpin), and the German Government, Federal Ministry of Education and Research un- der the project number 03WKCJ4D. Javier D. Fernández was funded by WU post-doc research contracts, and Axel Polleres was supported by the “Distinguished Visiting Austrian Chair” program as a visiting professor hosted at The Europe Center and the Center for Biomedical Research (BMIR) at Stanford University. Special thanks to Sebastian Neumaier for his support with the Open Data Portal Watch.